인공지능은 입력(입력값)과 출력(출력값)은 확인할 수 있지만 본질적으로 인간이 직관적으로 이해하기 어려운 상태(일명 '블랙박스 상태')를 가정합니다. 이를 쉽게 이해할 수 있도록 설명하였으며, 수학적 정확성보다는 원리 이해에 중점을 두었습니다. 이 설명은 프로그램을 제작하거나 심화된 이해가 필요한 경우가 아닌, 기본 개념을 파악하는 데 적합하게 작성하였습니다.
내용이 많아 1~2 부로 나누어 포스팅합니다
1부 기본원리
2부 산업
인공지능(AI, Artificial Intelligence)이란?
컴퓨터로 두뇌를 만들어서 우리가 하는 일을 시킬 수 있지 않을까?라는 의문에서 시작된 인공적으로 만든 지능. 사람의 사고 과정과 의사결정을 디지털 형태로 구현한 시스템.
인간의 지능적인 행동, 학습, 문제해결, 창의성 등을 기계가 이해하고 모방할 수 있도록 설계된 기술이며 인간을 뛰어 넘어 사고와 행동을 확장하는 기술.
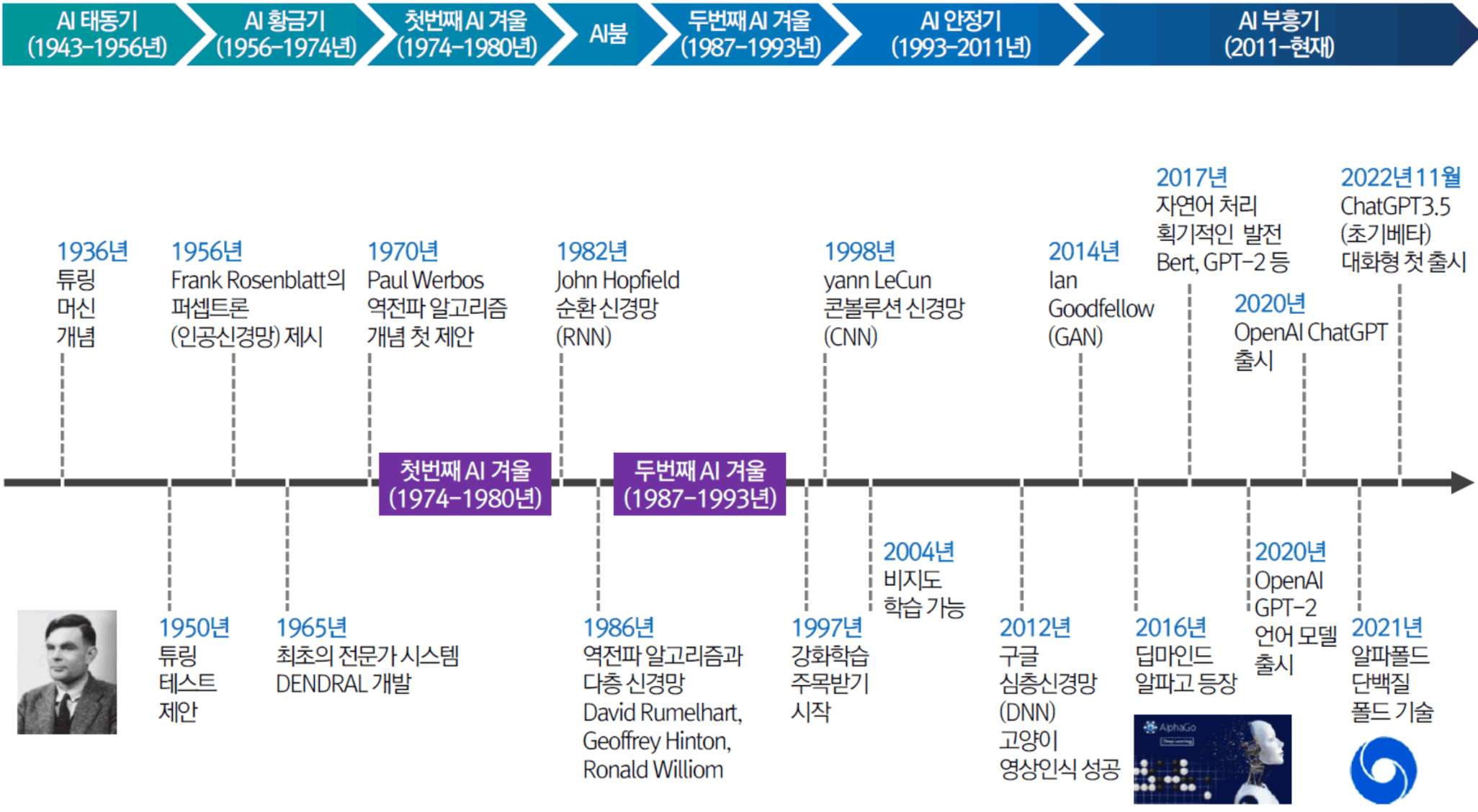
인공지능의 역사
AI 학습
인간처럼 사고하고 문제를 해결하는 능력을 갖추는 과정.
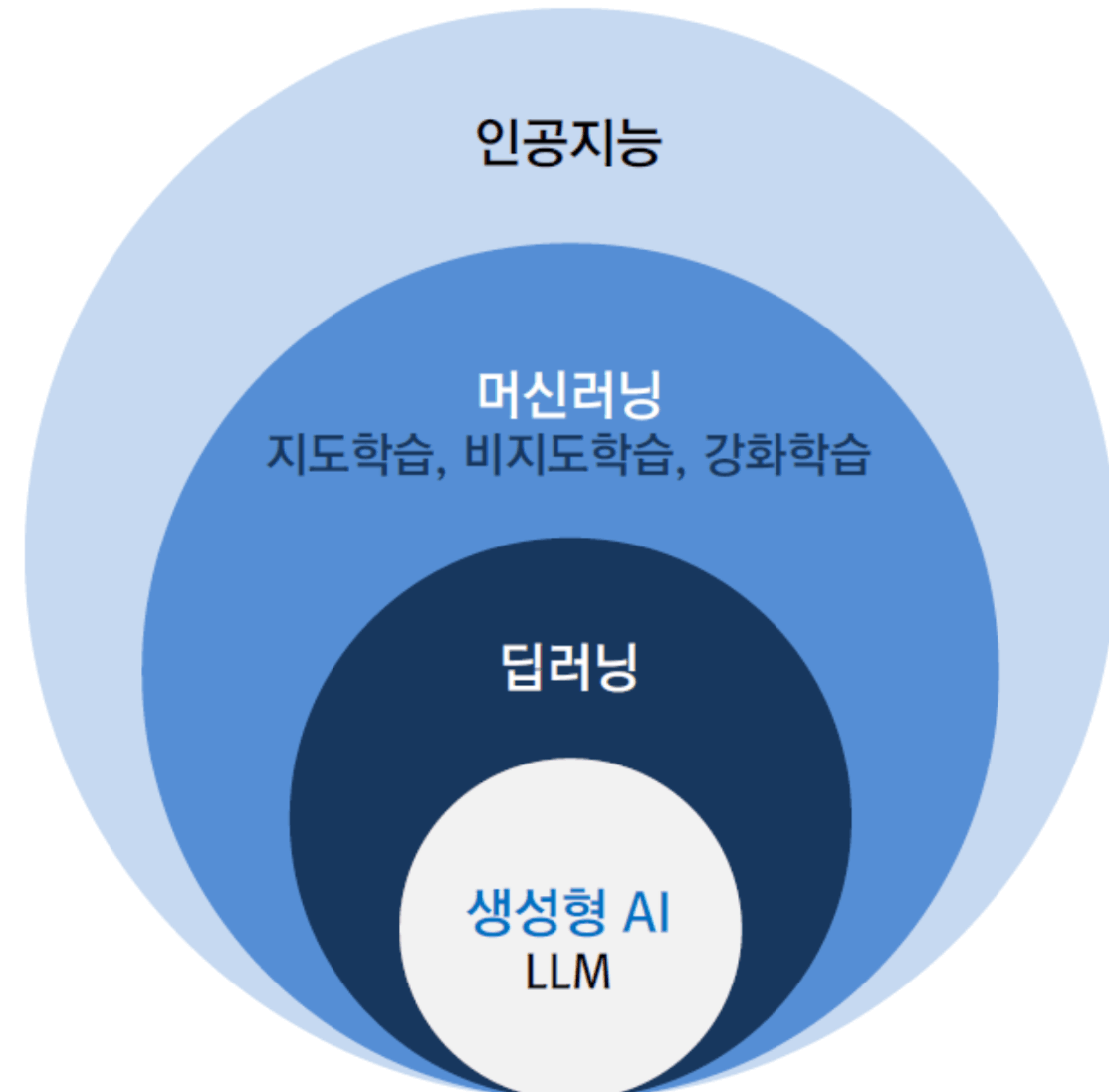
학습방법에는 기계가 학습을 한다는 개념의 머신러닝이라는 큰 범위 안에 딥러닝이라는 분야가 포함 되어 있음.
규칙기반 학습
인공 지능 초창기 학습. 인간이 논리와 절차를 정해주고 그 논리와 절차에 따라 결과 값을 도출해 내는 과정.
- 고양이의 귀모양, 눈모양, 입모양 등 모든 고양이의 특징을 입력 해줘서 고양이를 구분하는 방법. 하지만 그림처럼 인간은 식별할 수 있는 고양이를 귀를 가리고 몸을 가리자 AI는 식별을 하지 못하는 규칙기반 AI만의 한계가 있음.
- 유튜브나 영상서비스 알고리즘도 다르지만 비슷한 개념 내가 검색한 특정 키워드와 관련된 영상을 자동으로 계속 추천하도록 미리 규칙이 정해저 있음.

머신러닝
기계가 명시적으로 코딩(규칙이 정해져 있지 않은)되지 않은 동작을 스스로 학습해 수행하는 것을 말하며 인간이 최소한의 특징만 알려주고 알아서 학습하여 정답을 알아내는 방법.
딥러닝(neural network)
인간의 신경망을 본따 만든 학습방법.
스스로 학습하고 개선하는 대규모 신경망이며 다층 구조 형태의 신경망을 기반으로 함
인간 처럼 스스로 학습할 수 있도록 인공신경망을 구축해 많은 데이터로 훈련을 거듭할수록 성능이 향상됨.
그림, 언어, 음성인식과 같은 지정된 방식으로 정리되지 않은 비정형 데이터 처리가 가능.
비정형 데이터의 학습이 가능해지면서 패턴인식, 미래예측, 신호처리, 자율주행과 같은 활용 사례 증가.
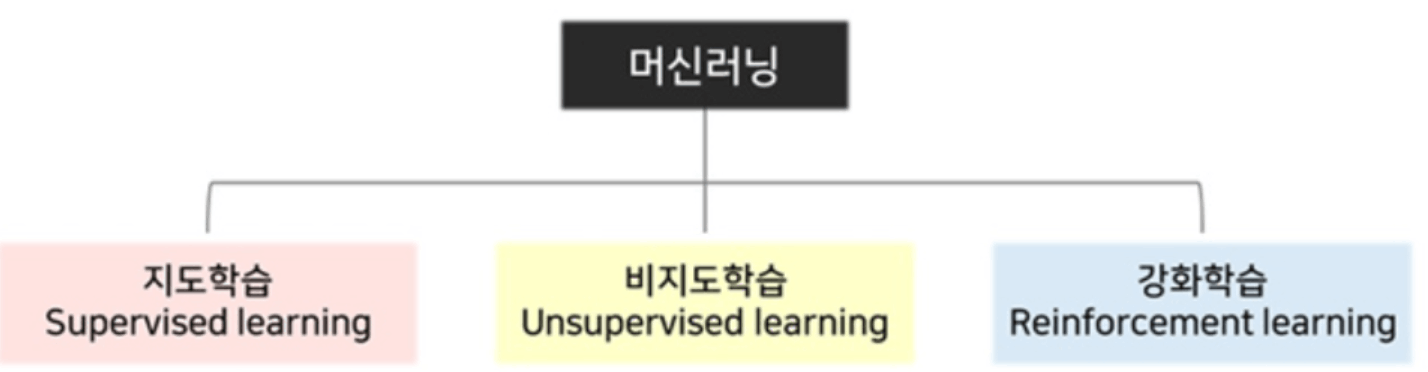
학습방법은 지도학습, 비지도학습, 강화학습으로 구분됨
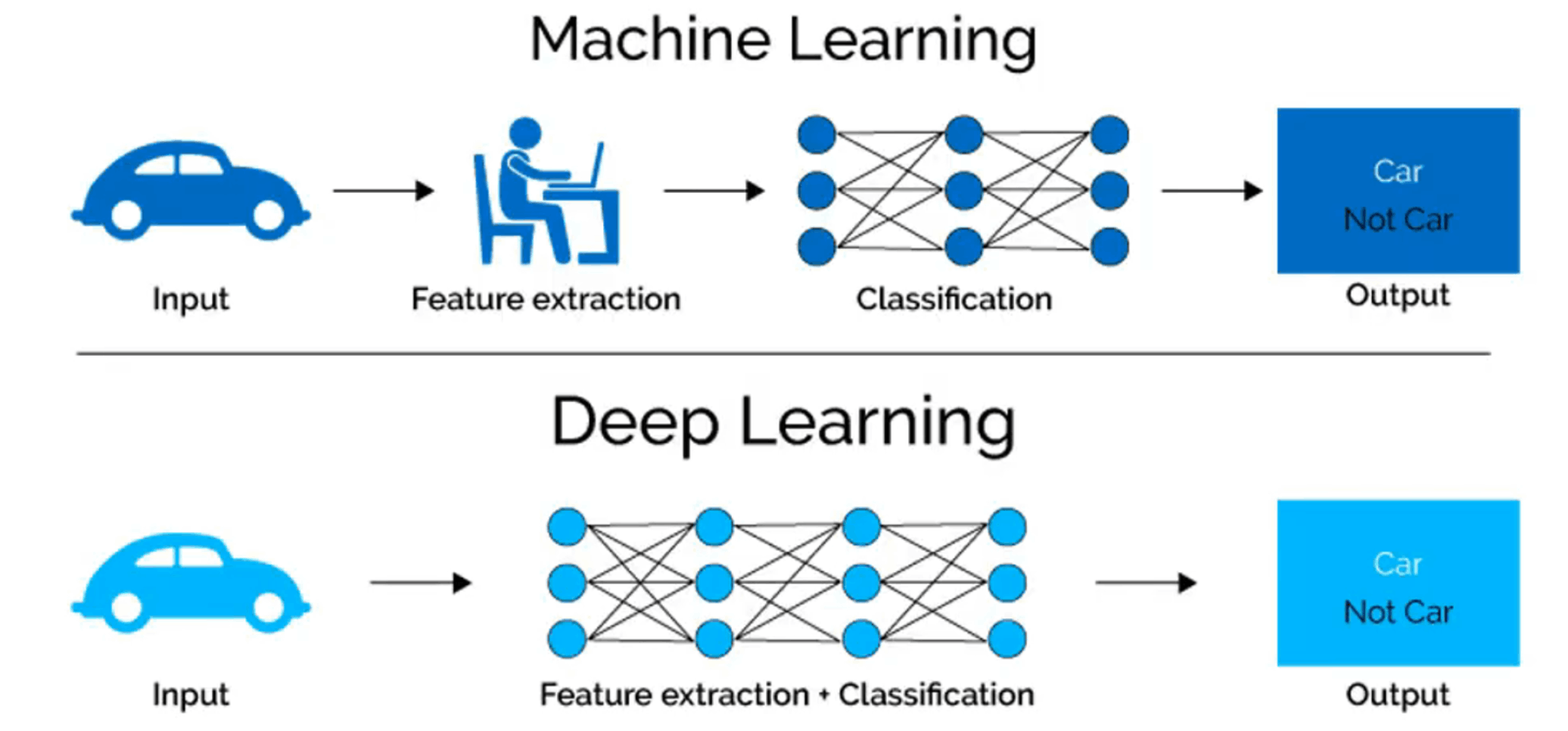
- 딥러닝은 머신러닝이라는 큰 개념에 속해 있는 학습 방법으로 머신러닝보다 딥러닝은 인간의 개입 정도가 적음. 물론 딥러닝도 인간의 개입이 없지 않지만 머신러닝에 비하면 거의 없다고 볼수도 있음.
딥러닝은 인간의 개입이 거의 없이 컴퓨터가 알아서 학습을 하는 개념이라고 쉽게 이해 할 수 있음.

- 사진과 같이 수천장의 여자 남자 사진을 주고 여자, 남자만 구분(레이블링)하여 데이터를 입력해 주면 컴퓨터가 알아서 여자는 머리가 길다 남자는 콧수염 있다 등등 여자의 특징, 남자의 특징을 구분하여 각각 특징에 대한 규칙을 스스로 학습함(지도학습, Supervised Learning)
인간식으로 이해하면 이런 것 이고 컴퓨터의 입장에서 이해해 보면 컴퓨터는 사진을 0,1로 이루어진 데이터(컴퓨터는 사진, 문자, 동영상을 뭐든 0,1로된 숫자로 모든것을 처리함)로 인식 하기 때문에 각각 사진의 데이터를 분석해서 비슷한 데이터 끼리 묶고 그것을 기반으로 규칙을 만들어냄(추후 추가 설명 함)
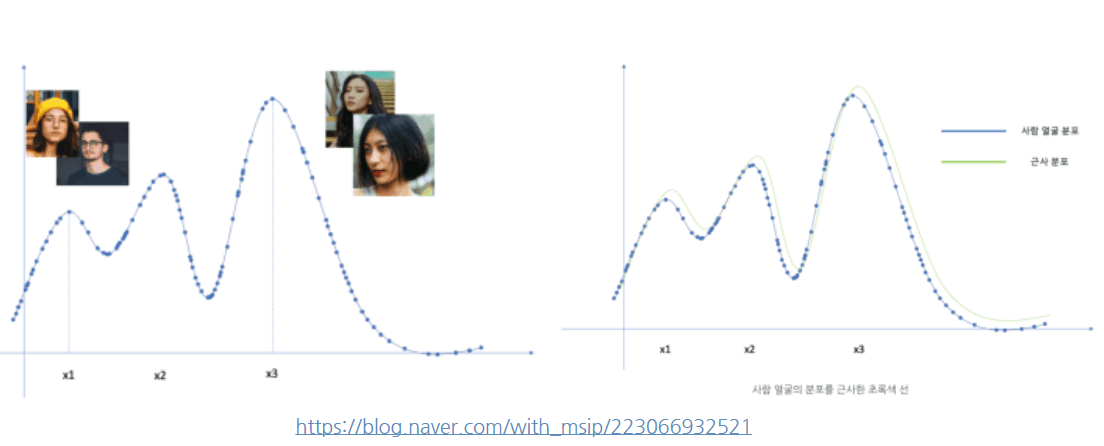
학습된 뉴럴네트워크가 사람을 구분하는 방법을 예로 들어 그래프로 도식화 해서 보면 , x1(y축)은 “안경을 쓴 사람”의 특징을 나타내는 지점. 모든 사람이 안경을 쓰는 건 아니지만, 꽤 많은 사람들이 안경을 쓰고 있기 때문에 그래프가 살짝 올라감.
반면, x3은 “검정색 머리카락”처럼 훨씬 많은 사람들이 가진 특징을 나타냄. 이 경우, 그래프가 훨씬 더 높아지게됨.
이런식으로 학습을 거친 ai가 사람의 얼굴에서 특징을 구분하여 분류를 하게되고 새로운 데이터가(사람사진) 들어 왔을때 분석하여 새로운 분포(우측그림 근사분포)를 생성, 비교하여 여자, 남자, 안경, 콧수염 같은 특징으로 인간, 여자, 남자를 구분하게 됨
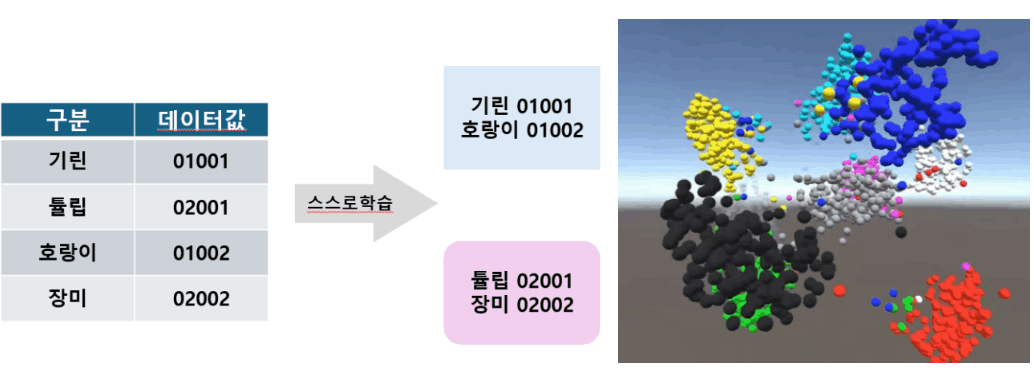
- 식물과 동물의 수만가지 사진을 컴퓨터에게 학습을 하도록 명령하면 컴퓨터는 좌측 그림처럼 기린과 호랑이를 데이터로 구분하여 비슷한것으로 인식(데이터 첫자리 둘째자리 01이 같음), 튤립과 장미를 비슷한것(데이터 첫자리 둘째자리 02가 같음)으로 인식하여 각각의 데이터를 특징별로 구분해서 우측 그림처럼 비슷한 특징끼리 구별(예를 들어 파랑색은 식물, 노랑은 동물, 검은색은 인간 등등, Labeled data)하여 군집화 시킴(비지도학습, Unsupervised learning, 멀티모달 학습)
학습 후 사자(01003)와 비슷한 것을 찾아 내게 명령하면 기린과 호랑이 값을 도출 하게됨. 만약 틀린 값을 도출한다면 지적을 해서 수정보완 하는 과정을 계속 반복하여(강화 학습) 최적화 시킴
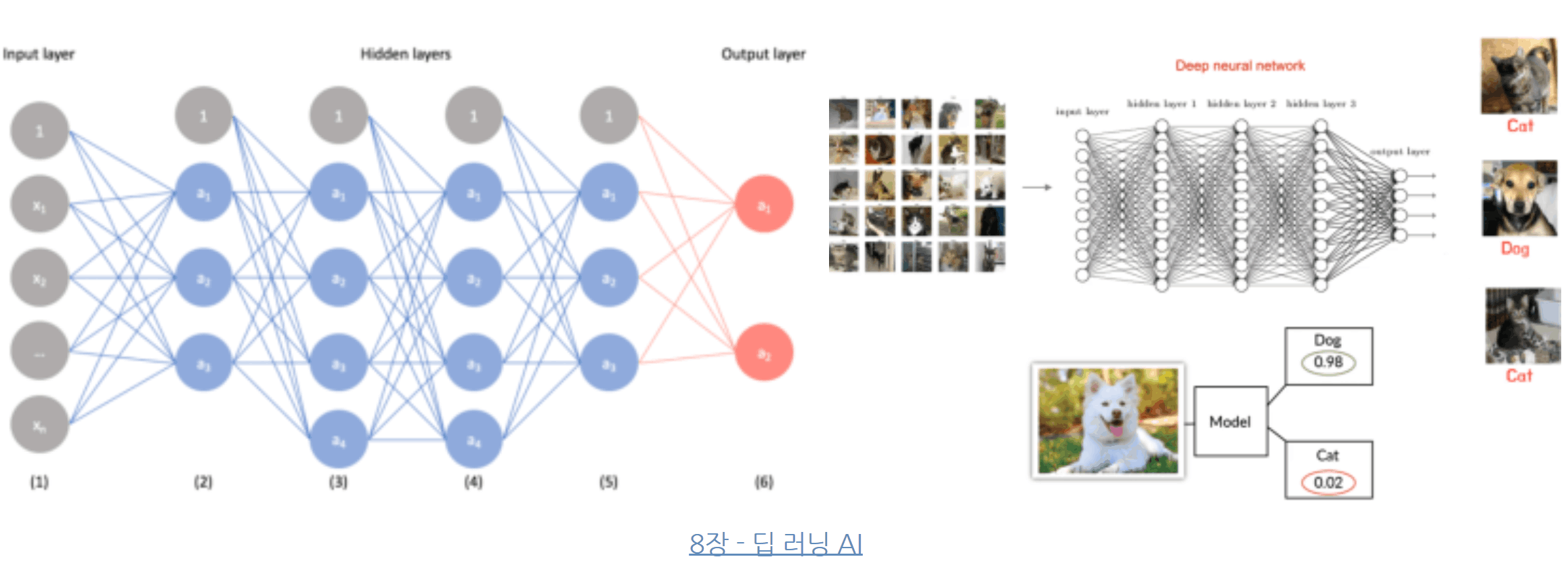
위에서 동그라미(레이어) 들의 연결이 한개의 뉴럴 네트워크 구조가 되고 개와 고양이를 구분해 내는 학습된 하나의 모델이라고 이해를 하면됨. 학습을 시킨다는 것은 저런 엄청나게 많은 레이어를 수천 수조개 만들어 하나의 모델(패턴)을 찾아 내는 과정임
입력값에 대한 가중치와 편향(파라미터)을 무작위로 설정해서 초기값을 기반으로 예측값을 계산하게 되고 코스트를 사용해서 오차를 계산. 경사하강법으로 실제 값과의 차이를 계산하고 그차이를 줄이기 위해 처음에 설정한 가중치와 편향을 조금씩 수정해가면서 파라미터를 조정하는 과정을 정답이 나올때 까지 무한 반복하게됨.
좀더 쉽게 설명해보면 쥐가 있으면 컴퓨터는 쥐모양을 사람처럼 눈으로 그림을 인지 하는 것이 아니라

넓은 단위의 픽셀들에 입력된 숫자들로 처리함(컴퓨터는 이진법으로 구분하나 사람이 보기 편하게 10진법으로 표현).
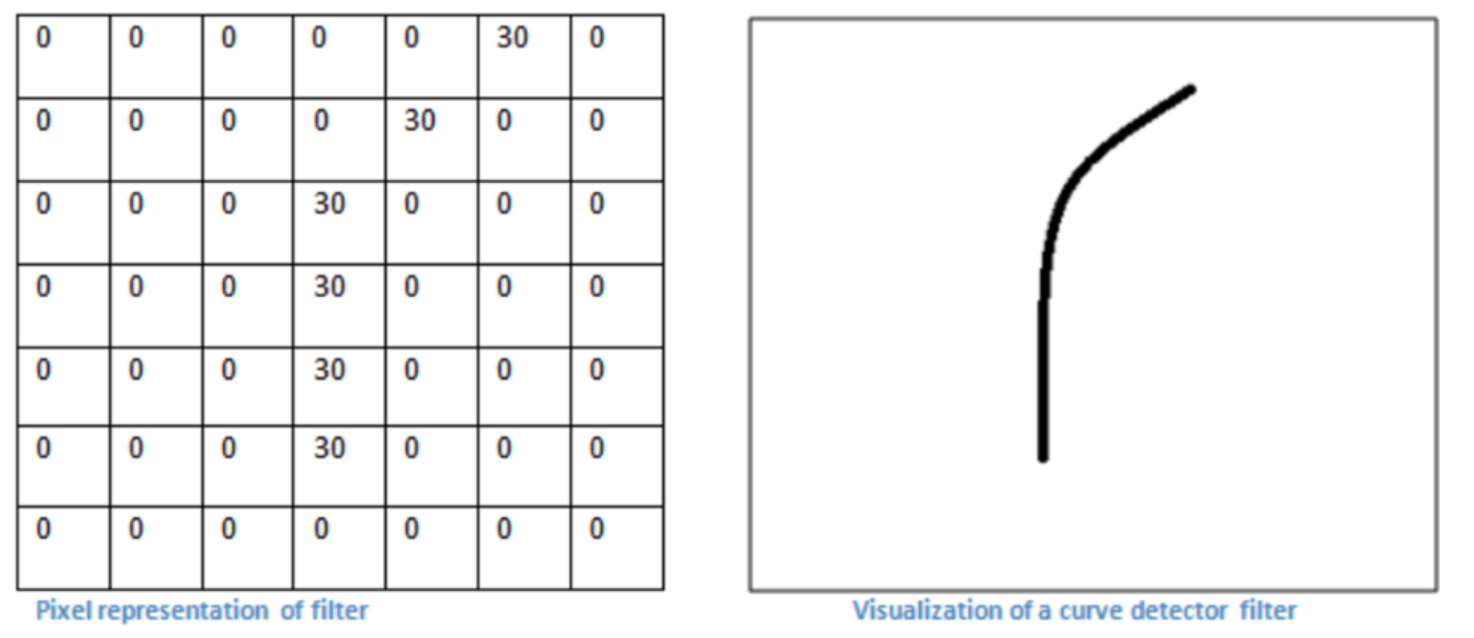
고작 엉덩이의 한부분이 픽셀에 숫자로 표현 되어 있는 것을 볼수 있음. 이런식으로 컴퓨터는 이미지를 픽셀 값으로 변환해 처리
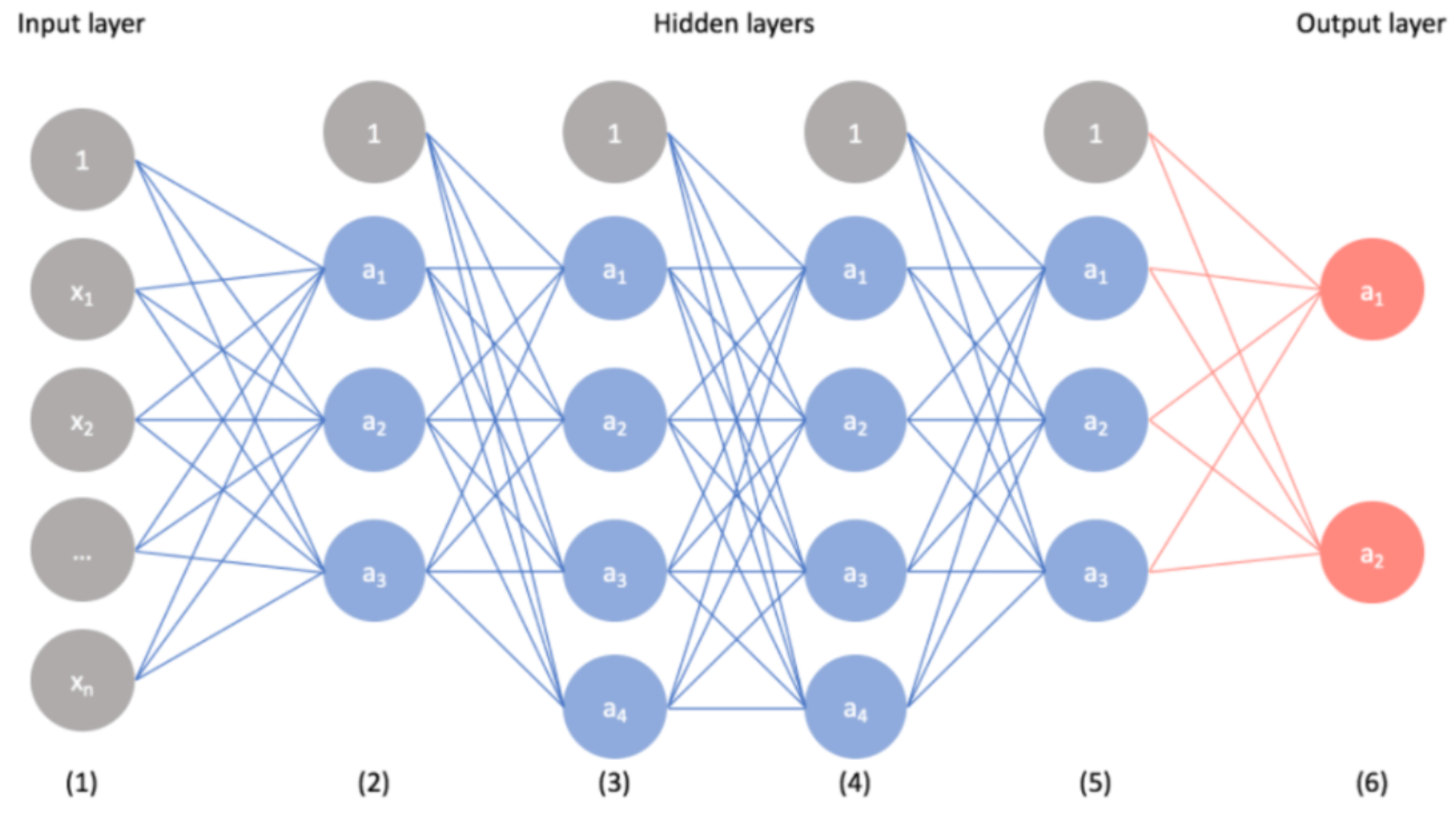
다시 네트워크 구조 그림으로 돌아와서 인풋값(input layer)에 수 많은 개사진을 넣게 되면 컴퓨터는 입력된 픽셀 값을 처리해 한 레이어당(동그라미 하나당) 비슷한 특징들을 예를 들어 개의 귀모양, 발톱, 털, 털색, 등등 수천 수만가지 비슷한 특징을 추상화하여 분류함
그림에서 히든 레이어(Hidden layers)중 첫줄은(2)단순한 선, 색상, 점,등 기본적인 특징을 학습하고 (3)은 더 구체적인 귀 모양, 발톱, 털, 등을 추상화하여 분류, 마지막으로 갈수록(Hidden layers 1 -> 5) 더 구체적인 특징들을 분류하게 되고 마지막에 아웃풋 레이어에서 그 분류한 것들을 조합하여 개의 사진을 임의로 만들게 됨. 그런데 개를 만들어 내지 못하고 이상한 동물이 나올 수 있는데. 그러면 처음부터 다시 오차의 수정을 하게 되고 그런 과정을 계속 무한 반복하게 됨.
한개의 레이어에 털이 100개씩 들어 있다고 가정했을 때 조합일 잘못되면 털이 작게 들어가거나 너무 많이 들어가게 됨. 아니면 귀가 3개가 달리거나 1개만 달리게 되는데 이것은 컴퓨터가 알아서 값을 조정하게 되면서 나타나는 당연한 현상이고 이를 정답사진과 비교해 수정을 하게 되는데 이러한 수정의 과정을 가중치와 편향을 조정한다고 하고 조정을 하게되는 값(사진에서 레이어를 연결하는 선들에 입력되어 있는 값을 변경)을 파라미터라고 하는데 파라미터가 많으면 많을수록 즉 수정을 계속 반복 할 수록 결과 값이 정확해 짐.
레이어(그림에 동그라미)와 레이어 사이에 연결된 선들은 숫자를 곱하거나 더하는 것을 의미하는 데 그 숫자(가중치를 변경)를 조정하여(털이 1만개가 정답이었는데 1천개만 들어 갔다면 선의 숫자를 처음보다 높이는 방법으로)편향을 수정하고 점점더 정답에 가까워 지게 됨.
그렇게 여러 숫자들을 조합하는 가중치와 편향의 고정된 값(첫번째 레이어의 털은 100을 곱하고 두번째 레이어의 귀는 2를 곱하고 등등)을 알게 되면 하나의 모델이 완성어 개의 특징을 학습하게 되고 하나의 뉴럴네트워크 모델이 완성.
간단하게 페턴을 만드는 방식을 수학적으로 이해 해보면 (수학을 꼭 이해할 필요는 없음.)
선영회귀 방법을 이용 패턴을 찾아내는 방법
1. 문제 상황
• 우리가 가진 데이터는 다음과 같다
• X: [1, 2, 3] (입력 데이터)
• Y: [3, 5, 7] (결과 데이터)
• X와 Y 사이에 어떤 규칙(함수, Y=f(x))이 있을까?
사람은 바로 “Y = 2*X + 1”이라는 규칙을 알 수 있지만, 컴퓨터는 이런 규칙을 바로 알지 못하고 수백번의 시행착오를 거처 스스로 찾아야함
2. 컴퓨터가 규칙을 찾는 방법
만약 초기가설을 H(가설함수) = w(무작위 수)*X + b(무작위 수). w라는 무작위의 수 곱하기 X + b라는 무작위의 수로 가설을 세우고 w,b의 숫자를 변경해 가며 패턴(함수)를 찾는 방법으로 진행을 한다면
정답은 w=2, b=1의 값이 되는데 여기에 무작위로 w=1, b=0을 넣게 되면 값이 1*1+0=1, 1*2+0=2, 1*3+0=3이 나옴. 표로 보면 초록색이 정답이고 분홍색이 오답.
정답 3,5,7과 오답과의 차이(cost)는 2,3,4 값이 나오고 이것을 최소제곱법을 이용 하여(cost)2/m(데이터의 갯수) = 29/3 이 나오게 되는데 무작위로 숫자값을 넣어 바꿔가면서 차이(cost)를 계속 줄여 cost가 0이 될때 까지 계속 반복함
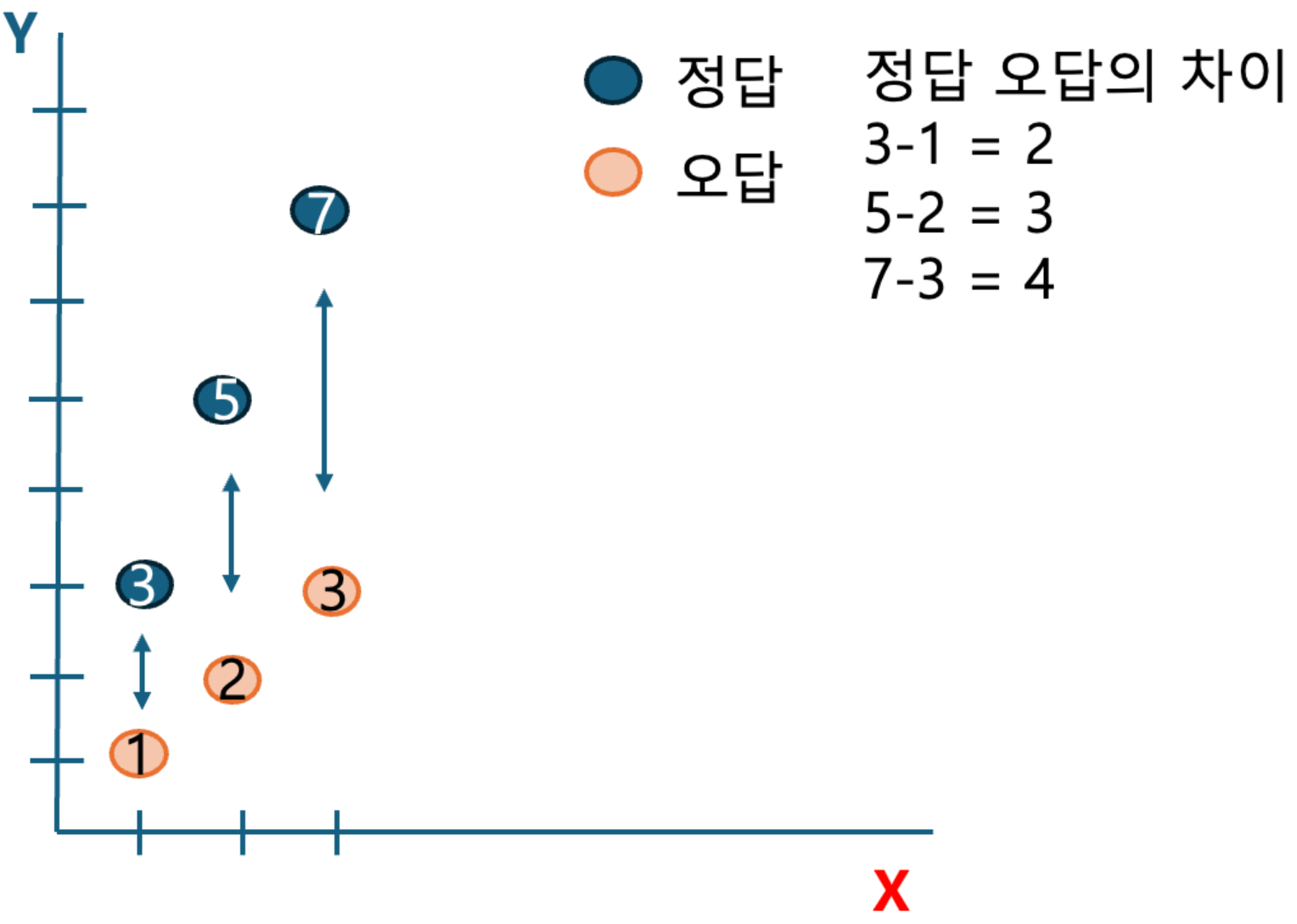
코스트가 0이 되었다는 말은 함수값을 알아 냈다는 말이되고 패턴을 학습했다고 이해할수 있음(개의 털 갯수 귀모양 발모양 치아모양 등등 패턴을 이해)
이제 X[1, 2, 3] Y[3, 5, 7]을 입력하면 함수값이 f(x) = 2x+1인 것을 컴퓨터는 알게 되었고 X값에 4를 넣으면 Y값이 9가 된다는 것을 학습하게 된 것(학습하지 않은 개사진을 넣어도 개인줄 알게 되고, 패턴이 다른 고양이는 개가아니라고 인식 함). 이렇게 개과 고양이의 패턴(함수)을 학습하게 되면 다음에 수천개의 동물사진에서 개와 고양이를 구분할 수 있게됨.
뉴럴 네트워크 최적화(추론)
규칙을 알게 되어 뉴럴 네크워크 모델이 생성되게 되면 최적화 과정을 거침.
예를 들어 수많은 개사진을 학습한다고 가정하면 개의 사진 외에도 주변 환경도 분석하게 되는데 개 배경사진은 중요하지 않는 것으로 구분하여 개의 특징만 구분함.
개의 특징을 구분하는데 100가지특징으로 구분했다면 거기서 20가지를 제외하더라도 결과값에 크게 차이가 없다면 20가지 특징을 제외하는 과정 가장 효율적인 구분에 도달 하는 과정. 그렇게 경량화 최적화 과정을 통해 불필요한 소모를 줄여 추론이 좀더 원활하게 만듬(경량화 모델 ex.딥시크)
AI 형태 및 학습방법
LLM(Large Language Model, 대형 언어 모델)
대표적인 모델 : chat GPT, Copilot, Gemini
아주 방대한 텍스트 데이터를 기반으로 학습해 자연어 이해, 생성, 번역, 요약 등 다양한 언어적 작업을 수행할 수 있는 모델
언어학습방법
프리트레이닝(Pretraining): 모델이 언어의 기본적인 구조와 패턴을 학습하는 과정
대규모의 텍스트 데이터(예: 책, 인터넷 글, 위키피디아)를 사용하여, 모델이 언어의 문법, 단어 간의 관계, 어휘의 사용법 등 언어의 체계적인 구조와 특정 단어, 문장, 또는 텍스트가 어떤 배경, 상황, 또는 주제에서 사용되고 있는지 맥락을 이해하도록 학습
* 자연어 처리의 어려움

복잡성 : 언어, 상황, 환경, 지각 지식의 학습 및 표현이 복잡 : 명사 뒤에 조사의 종류에 따라 같은 말이지만 다름
애매성 : 인간의 언어는 기계어인 프로그래밍 언어와는 다름 = 사과의 여러뜻
종속성 : 인간의 언어를 해석하기 위해서는 실제 세상과 상식, 문맥 정보 등이 필요
AI가 자연어를 처리하는 방법(자연어 처리,natural language precess, NLP)
인간의 언어와 표현을 컴퓨터가 처리할 수 있도록 하는 계산 기법
처리순서 : 형태소분석 -> 품사태깅 -> 구문분석
(토큰화, 주어진 문장에서 의미부여가 가능한 단위를 찾는다)
EX) 화분에 예쁜 꽃이 피었다
형태소분석 : 화분/ 에 / 예쁘 / ㅁ/ 꽃 / 이 / 피 / 었 / 다.
품사태깅 : 화분(명사) 에(조사) 예쁘(어간) ㅁ(어미) + 꽃(명사) 이(조사) + 피(어간) + 었(어미) 다(어미)
구문분석 : 주어 동사 목적어등 문장의 구성 요소 간의 관계를 파악
-
문장 구조 파악
- 주어: "화분에 예쁜 꽃" ('화분에'는 부사구, '예쁜 꽃'은 주어 역할)
- 동사: "피었다" ('피-' 어간과 '-었다' 어미로 구성된 술어)
- 수식어: "예쁜" ('꽃'을 수식)
-
관계 파악
- '화분에' → 장소를 나타내며 주어 '꽃'과 연관됨.
- '예쁜' → 주어 '꽃'을 수식함.
- '피었다' → 주어와 직접 연결된 동사 (주어와 술어 관계).
-
의미분석 : 문맥, 문장간의 관계등을 고려하여 정확한 의미를 문맥에 따라 구분
-
문맥적 해석
- '화분에'는 위치를 나타냄.
- '예쁜 꽃'은 특정한 아름다운 꽃을 의미.
- '피었다'는 과거에 꽃이 피어난 사건을 묘사함.
-
의미 파악
- 이 문장은 '화분'이라는 특정 장소에서 '예쁜 꽃'이 피어난 사실을 전달하는 설명문이다.
- 전체 의미: 화분 안에서 꽃이 피어난 아름다운 상태를 묘사하고 있음.
-
추론
- '예쁜'이라는 형용사로 인해 화분의 꽃이 시각적으로 아름다운 상태임을 강조.
- '피었다'라는 과거형 동사로 사건이 완료되었음을 암시.
학습방법

인터넷에 있는 수천 수만개의 문서에서 단어를 무작위로 학습시키면 한 문서에 포함되어 있는 단어들 끼리 군집화하고 관련있다고 학습함. 가령 그림처럼 과학과 연관 된 단어가 다른 문서에도 비슷하게 연관되서 나오면 과학은 박사 또는 논문과 연관되어 있을 확율이 높다고 예측함
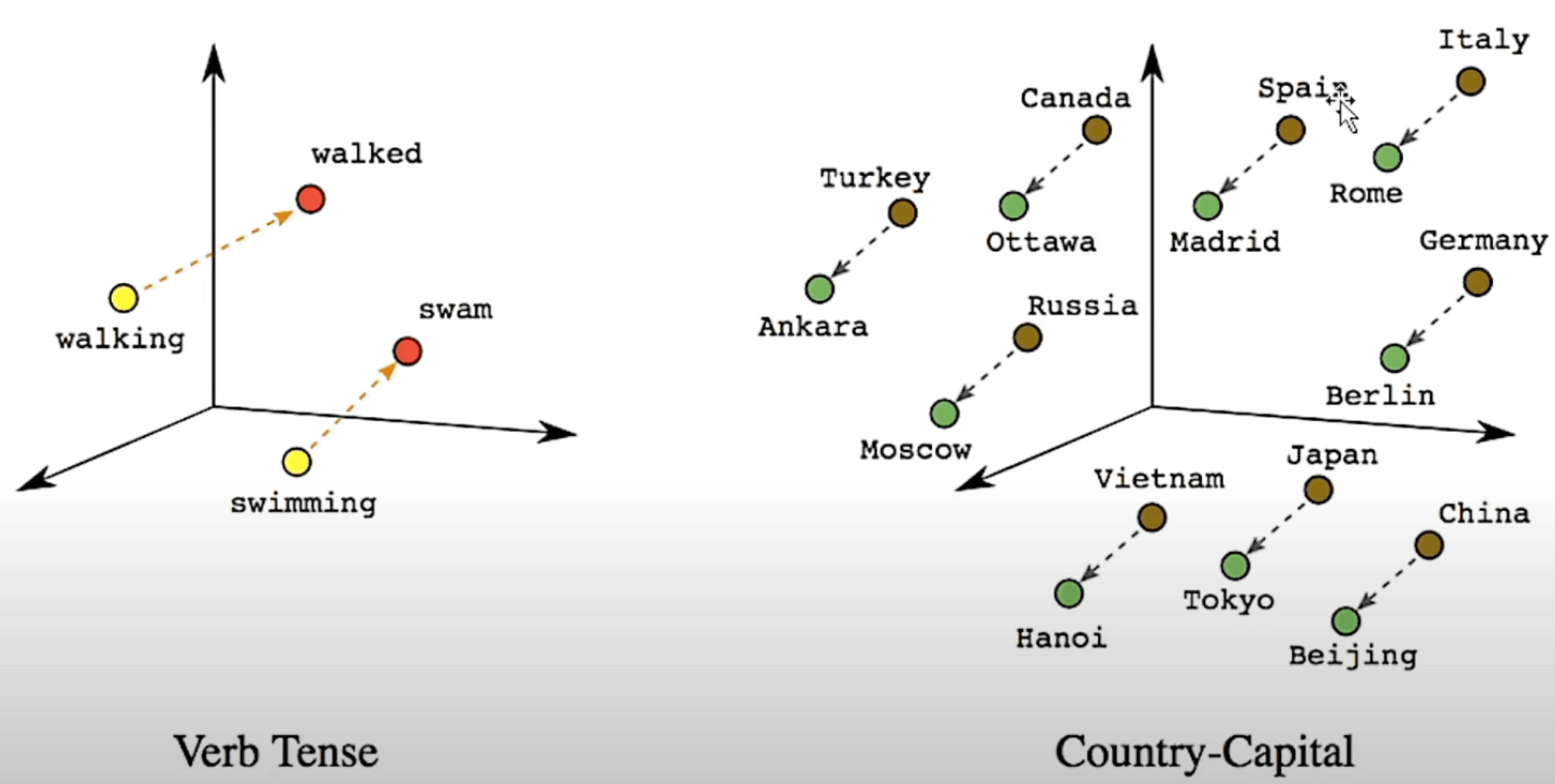
이 공간을 다차원의 벡터 공간(다차원공간임)이라고 하는데, 공간에서의 위치가 특성을 나타내며 점(벡터)과 점사이가 가까울 수 록 비슷한 특성을 가지고 있다고 인식을 하게 됨(벡터 = 숫자들의 집합. 개 사진처럼 컴퓨터는 단어도 숫자로 인식하는데 이 숫자들의 집합을 벡터라고 함. 모스코바 벡터 = 1.5,0.53.44 이런식)
LLM은 단어를 벡터로 변환하여 다차원 공간에 배치하며, 각 단어의 관련성에 따라 가까운 위치에 놓이게됨. 예를 들어, 모스크바라는 단어는 벡터 공간에서 푸틴, 러시아, 유럽 같은 단어들과 군집을 이룸. 군집을 이루지만 관련성에 따라 거리가 다름 푸틴과 모스코바가 모스코바와 유럽보다 가깝게 배치됨(이 과정을 임베딩 이라고 함Embedding).
어차피 사전적으로 보면 한단어를 설명하는 것도 다른 단어이기 때문에 인터넷에서 수십수만개의 단어를 저런식으로 가까운 단어별로 학습하게 되면 사전적으로 단어를 설명 할 수 있게 되는 원리
학습을 완료하여 어느 정도 뉴런모델이 완성되게 되면 인터넷에서 문장을 수집한 후에 단어를 랜덤으로 지워 (빈칸)을 만들어 스스로 문제를 만들어 내고 답을 완성해 가면서 정확도를 높임.
글을 쓰게 되는 원리를 보면, 모델은 학습된 데이터를 바탕으로 가장 가능성 높은 단어(군집에서 가깝게 있는)를 선택하여 문장을 생성하며, 요청된 형식(예: 논문, 소설)에 따라 어휘와 문장 구조를 조정 하게됨. 이는 단순히 단어를 무작위로 나열하는 것이 아니라, 문맥과 의미를 고려한 최적화된 단어 조합을 통해 결과를 생성 함. 이미 학습이 완료된 논문, 소설 모델의 고정된 규칙에 따라 작동하며, 이를 통해 정확하고 자연스러운 문장을 생성할 수 있는 원리
쉽게 말해 개를 분석하는 법칙(모델, 함수)를 고정한 것 처럼 논문, 소설을 만드는 모델이 이미 학습되어 있고 그 모델을 바탕으로 모스크바와 가장 벡터공간에서 가까이 군집을 형성하고 있는 단어들의 조합으로 글을 쓴다고 볼 수 있음.
예를들어 "과자 만드는 방법을 알려줘"라는 지시를 내리게 되면
1. 과자 / 만드/는/ 방법/을/ 알려줘/라고 토큰화(형태소 분석)
2. 각각 단어 뜻을 파악
3. 과자 = 조리퐁 베베 쿠키 빵 등등 벡터상 가까운 단어들 추론
4. 만드는 = 기존에 학습되어 있는 문장들에서 만드는이라는 단어가 많이 포함된 문장에서 원리 구성을 나타냄을 추론
5. 방법 = 상기와 같은 원리로 순서 제조법등을 나타냄을 추론
6. 알려줘 = 요청임을 추론
상기 과정을 거처 과자를 만드는 방법을 알려 달라는 요청임을 추론하고 임베드상에 과자과 가까운 쿠키등을 만드는 방법을 쿠키와 가까이 있는 밀가루 성탕등을 이용하여 요리방법에 대한 글 구조를 바탕(인터넷 검색 참고하여)으로 문장을 구성하게됨.
AI 학습과정과 인간 언어 학습 과정의 유사성
1. 기초 단계: 간단한 언어 패턴 학습
-
LLM 초기 학습: 모델은 대량의 텍스트 데이터(인터넷에서 수집한 데이터 등)를 사용하여 기본적인 언어 구조, 단어의 빈도, 간단한 문장 패턴 등을 학습.
-
예: "고양이는 귀엽다" 같은 단순 문장에서 단어의 상관관계, 문법적 순서를 익히는 과정.
-
인간의 초기 학습과 같이 어린아이가 "사과가 빨갛다"와 같은 간단한 문장을 읽으며 기본적인 문법과 단어의 사용법을 배우는 것과 비슷함.
2. 중간 단계: 점진적 확장과 복잡한 패턴 학습
-
LLM의 점진적 학습: 모델은 더 복잡한 데이터와 문맥을 학습하기 시작. 소설, 뉴스, 과학 논문 등 다양한 형태의 텍스트를 학습하면서 긴 문장, 추론, 문맥을 이해하는 능력을 확장.
-
예: "경제 뉴스 기사"를 통해 전문 용어와 추론적 문맥을 이해하는 법을 배우는 단계.
-
인간의 학습: 초등학생이 짧은 동화책에서 벗어나 역사나 과학 교과서를 읽으며 논리적 사고, 복잡한 문장 구조, 그리고 추론적 사고를 배우는 것과 유사.
3. 고급 단계: 심화 학습과 응용 능력 확장
-
LLM의 심화 학습: 다양한 주제에 대한 깊이 있는 데이터(예: 철학적 논문, 고급 과학 자료 등)를 학습하며 고도의 추론, 비판적 사고, 상상력을 요구하는 질문에도 답할 수 있는 능력을 갖추게 됨.
-
예: "인간의 자유 의지가 존재하는가?" 같은 철학적 질문에 대한 복잡한 답변 생성.
-
인간의 학습: 고등학생이나 대학생이 심화된 학문적 주제를 배우며, 학습한 내용을 응용하고 창의적으로 사용하는 단계.
4. 응용 및 실용적 지식 활용
-
LLM의 적용: 학습한 방대한 지식을 바탕으로 실용적인 작업(예: 코딩, 번역, 글쓰기)을 수행하고, 다양한 주제의 문제를 해결하는 데 사용됩니다.
-
인간의 적용: 성인이 된 후, 배운 지식과 경험을 사용하여 실제 문제를 해결하거나 직업적 과제를 수행하는 단계와 유사합니다.
LLM 하드웨어 처리과정
LLM로딩(SSD에서 디램으로 LLM 신경망로딩)-> 사용자 문의 -> CPU가 단어들을 숫자로(컴퓨터언어)로 변환 -> GPU가 각각 단어 별로 추론(단어 한개당 수만번의 계산)하여 취합 -> 취합된 단어들을 CPU가 조합 -> 사용자 전달
추론에서 최적화를 거치게 되면 최대한 램 사용량을 조절 할 수 있으나 대량의 문서나 이미지, 영상의 경우 입력 값을 분석하는데 많은 램을 사용하게 되고 반드시 많은 GPU의 코어가 필요하기 때문에 아무리 최적화 한다고 해도 한계가 있음.
ChatGPT답변 도출 원리 단계
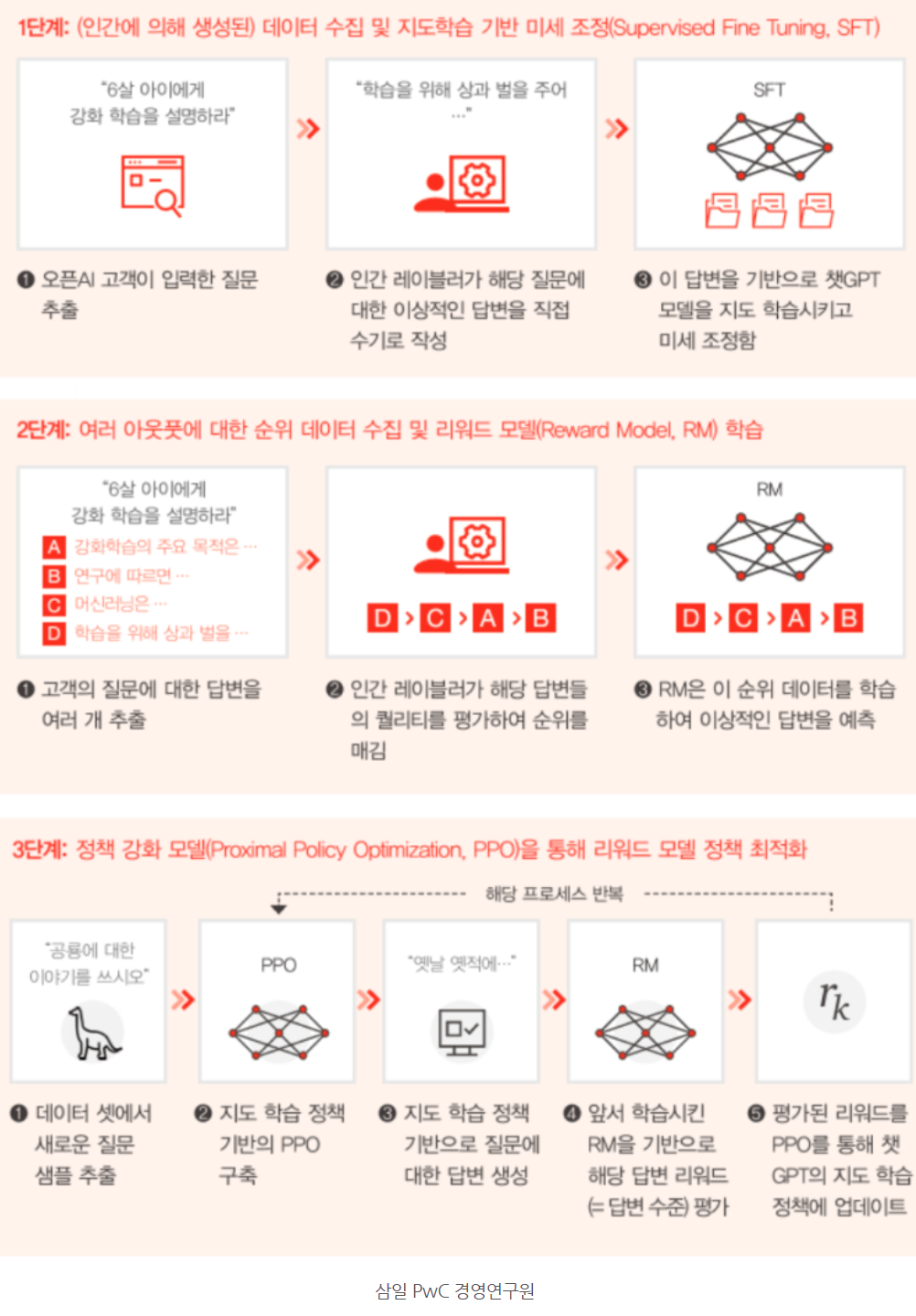
사람이 직접 질문에 대한 이상적인 답변을 수기로 작성하여 데이터 세트를 만들고 이 것을 기반으로 모델을 학습시키며 파라미터 조정을 하면서 답을 수정해나감.
질문에 대한 답변을 컴퓨터가 나름대로 여러가지 버전으로 작성을 하면 그것을 사람이 평가하여 가장 높은 점수 매김.
새로운 질문 샘플을 컴퓨터가 알아서 추출하고 알아서 답을 만들어 기존에 지도학습한 데이터를 바탕으로 수정 보완을 알아서 최적의 답변으로 학습을 이어감.
이미지, 영상생성 AI
이미지 생성이나 영상 생성을 할 수 있는 AI 기술
대표적인 모델 : Midjourney, adobe, sora, DALL-E
학습방법
GAN(generative adversarial network / 적대적 생성 신경망)
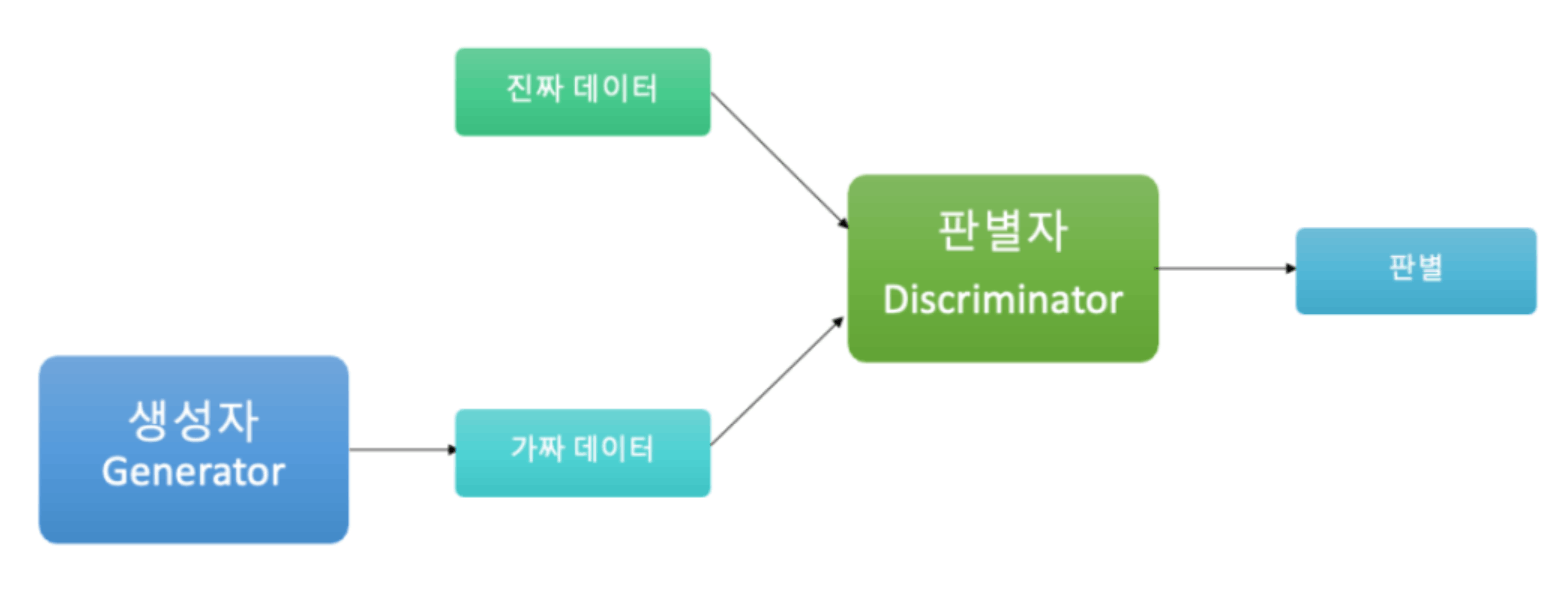
- 생성자 generative
생성자는 진짜 같은 가짜를 만들어 판별자가 가짜를 진짜라고 생각하게 만들어야함

- 판별자 discruminator
판별자는 진짜를 진짜로, 가짜를 가짜로 판별 해내야함
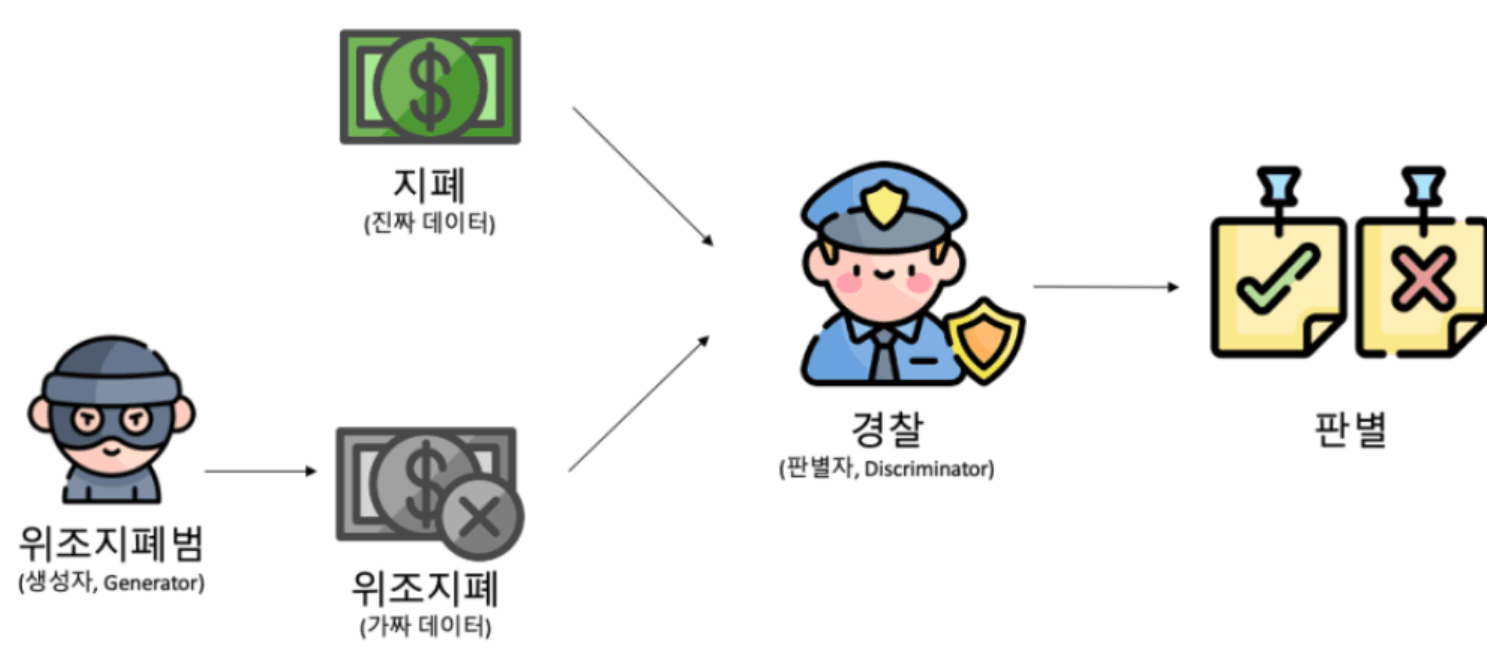
경찰과 위조 지폐범을 예시로 들어보면 위조지폐범이 위조 지폐를 생셩하게 되면 경찰은 지폐가 위조인지 판별하게 됨. 위조 지폐범이 잡히지는 않으면서 경찰이 지폐만 계속 판별해내어 사람들에게 판별법을 알려 준다고 가정해보면 위조 지폐범은 최대한 비슷하게 만들기 위해 노력할 것이고 경찰은 변별력을 높이기 위해 최선을 다하게됨. 그렇게 서로 발전하다 보면 마지막에 위조 지폐범이 거의 진짜 같은 위조지폐를 만들게 된다는 원리를 이용함. 판별자에게 걸리지 않기 위해 점점 더 진짜 같은 가짜 데이터를 만들 수 있게됨
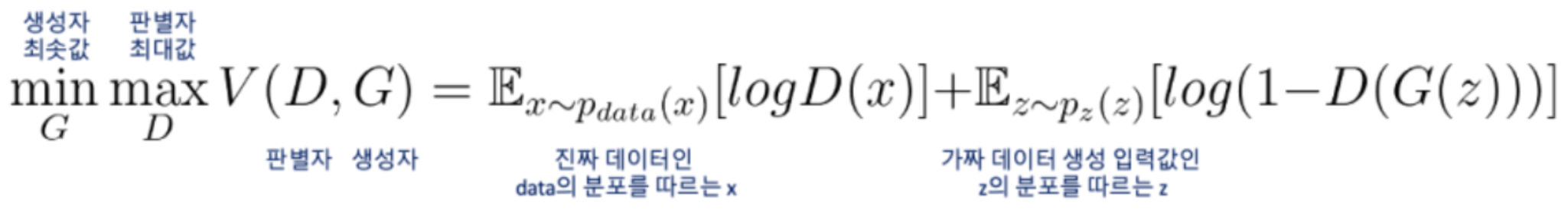
개를 예로 들면 AI 딥러닝을 통해 개의 이미지를 학습하게 되었다고 가정을 하고, 개의 이미지를 그려보라고 하면 처음에는 이상하게 그려낼 것이나 판별자가 틀렸다고 계속 지적을 하고 다시 그리고 다시 그려 판별자가 개의 그림이 맞다고 할때 까지 그림을 그려 내는 것. 그렇게 학습된 생성형 데이터가 미리 딥러닝을 통해 학습한 데이터와 합쳐저 다음에 개를 구분할때 더 완벽하게 개를 구분 할 수도 있게됨.
이런식으로 학습을 반복하여 거의 인간의 지능과 비슷하게 추론과 생성을 할 수 있게 되는 원리

그림, 영상을 만드는 원리
GAN방식에 따라 최대한 입력값과 비슷한 허구를 만들어 내는 것(픽셀에 숫자를 입력해서)을 학습하고 반복하여 모델을 만들고 그 모델을 바탕으로 주문자의 요청에 따른 결과물을 만들어냄.
영상은 프레임단위로 그림을 만들면 되기때문에 그림을 만드는 행위를 반복.
음성생성 및 작곡 AI
대표적인 모델 : Speechify, Veed.io, Voicemod
음성 인식 원리
소리는 공기를 타고 전달이 됨.
공기의 주기적인 진동 수축과 팽창이 발생해야만 소리 라는 정보가 됨. 아니면 그냥 바람이랑 똑 같음.
공기분자가 얼마나 크게 움직였나, 파동이 큰가, 어떠한 단위 시간동안 얼마의 파동이 생겼나로 구분 가능
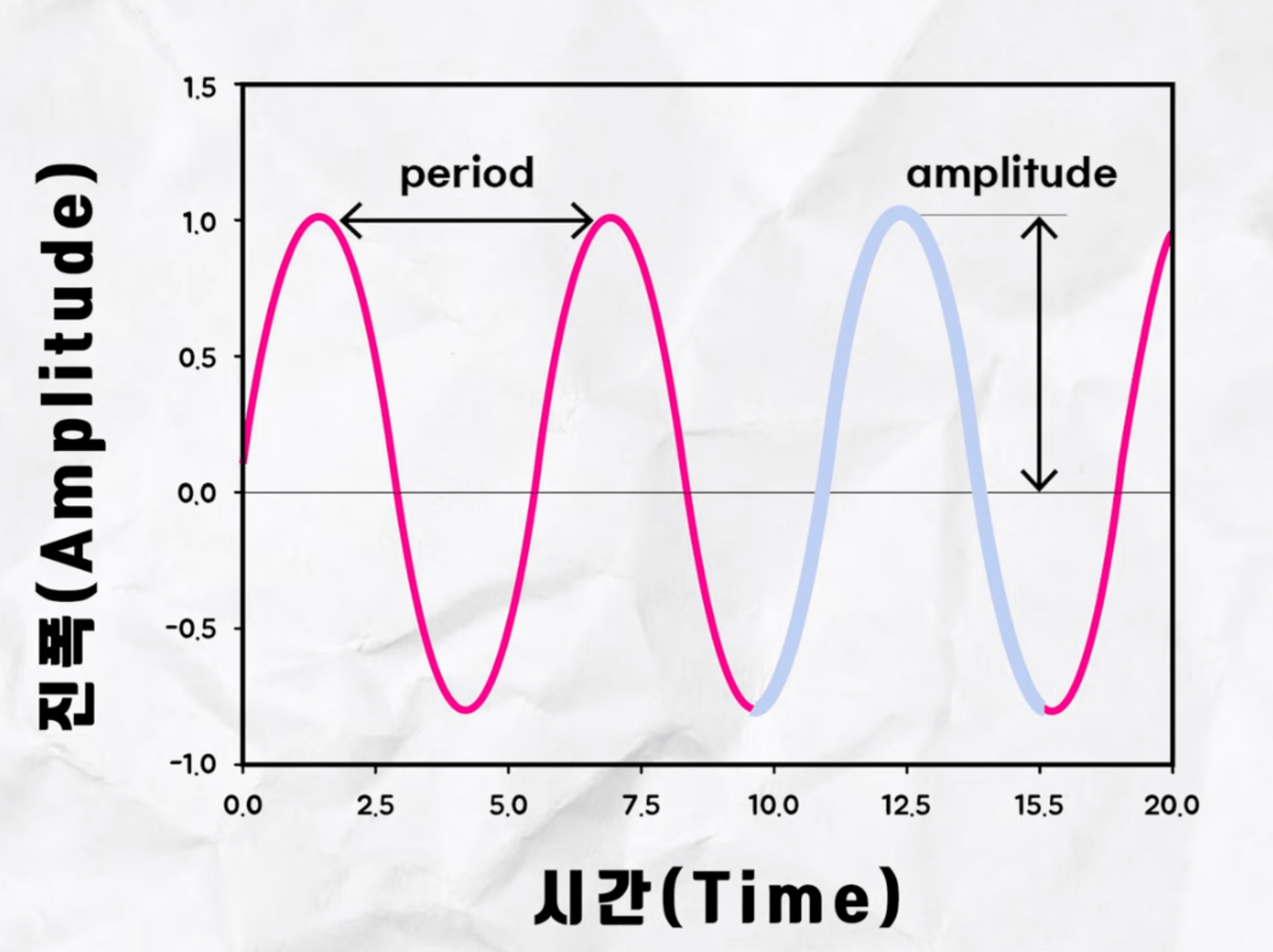
* amplitute = 진동의 폭, period = 주기 진동 고점 저점 간의 시간 한번진동의 시간
1초에 진동하는 횟수 =Hz 100HZ = 1초에 100번 진동
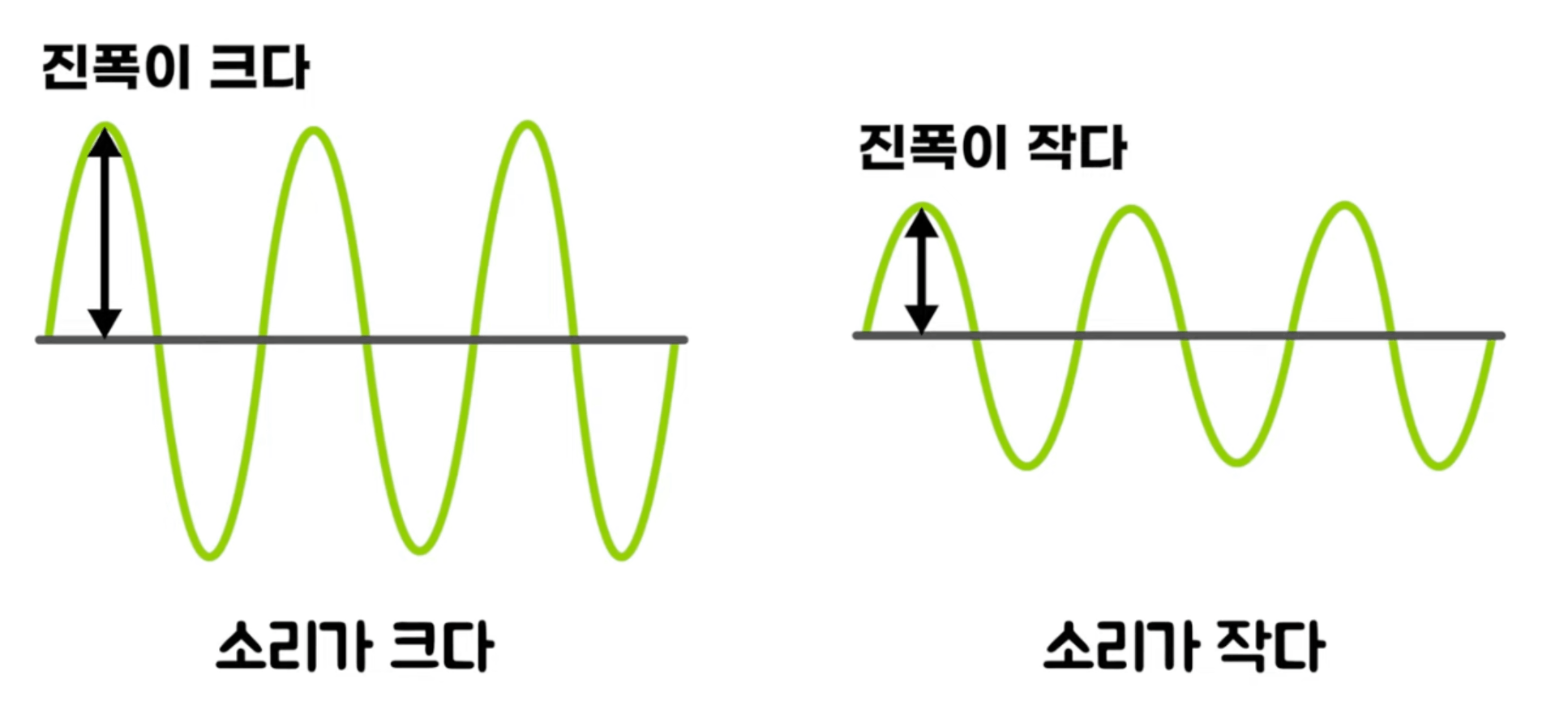
보통 진폭이 크면 소리가 크고 진폭이 작으면 소리가 작음
소리를 컴퓨터가 인식하게 되는 과정(샘플링)
마이크에 대고 말을 하면 마이크에 다이어플램(진동판)을 흔들게 되고, 이 진동이 음파의 진폭과 주파수에 따라 다르게 움직임-> 코일 및 압전소자등을 통해 전압신호로 변환 -> 전압은 아날로그 신호로 진폭과 주파수를 표현 -> 디지털 신호로 변환(소리의 파동의 높이를 일정한 간격으로 좌표값을 지정하여 숫자로 변환)
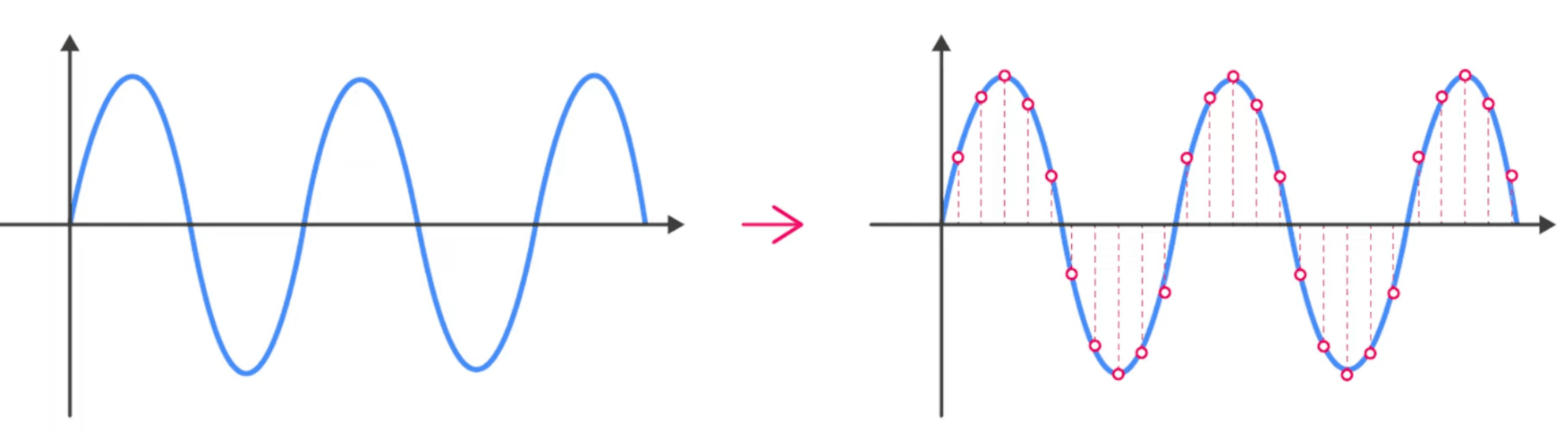
우측의 그림처럼 진폭의 높이를 일정한 간격으로 좌표값으로 지정하여 숫자로 변환
보통 1초에 44.1KHz(44,100개의 진폭 값) 소리를 샘플링함.
1초에 초당 44,100번의 진폭을 65,536단계(16bit)의 소리로 구분하여 숫자로 표현.
지도학습
애플을 숫자로 변환 하게 되면 0.1,0.4,0.5이런식의 숫자 배열이라고 가정하면 먼저 라벨링(숫자로 표현)된 단어를 준비하여 사람이 애플 파동의 숫자와 애플단어의 라벨링된 숫자와 매칭을 시켜줌.
딥러닝
개사진을 훈련하는 것과 같이먼저 라벨데이터를 알아서 훈련하고 이후에 애플 발음을 샘플링한 데이터(진폭값0.1,0.4,0.5)를 입력하면 모델이 알아서 애플이라는 단어로 변환하려고 시도. 틀릴경우 파라미터를 조정하여 정답에 가까워지려고 노력함.
학습을 완료하여 샘플링 데이터와 라벨 데이터의 매칭이 끝나게 되면 그 이후에는 LLM 작동방식과 동일하게 관련성있는 단어들의 나열로 말을 하거나 작곡을 하거나 하게 되는 원리.
추론(실시간추론)
AI가 기존에 학습된 데이터를 바탕으로 입력된 새로운 데이터를 분석하여 결과값을 도출하는 과정
추론과정
예를 들어 개와 고양이를 인식하는 학습된 뉴럴 네트워크 모델이 있다고 하면 개 이미지를 입력 값에 넣게 되면 입력값만 분석하여 기존에 학습되어 있는 모델에서 간단하게 특징만 비교하여 결과 값을 도출 함.
자연어 처리과정을 예로 들면 이미 AI는 자연어 단어에 대한 뜻을 분석하여 벡터상에 분류가 되어 있음
벡터상 분류된 단어들은 비슷한 단어 그리고 많이 쓰이는 단어들 끼리 뭉처 있음
분류되어 있는 값은 정해진 것이고 만약 사용자가 자연어로 새로운 단어를 입력하면 문맥만 이해를 하면 되기 때문에 과정이 학습 보다는 단순함
사과를 했다 사과를 먹었다를 예로 들면 이미 사과를 먹었다 = 음식을 먹다와 가까운 벡터 값을 가지고
사과를 했다 = 용서와 비슷한 벡터값을 가지고 있음 이미 입력되어 있는 값을 호출하면 됨
멀티모달(생성형AI, AI에이전트)
기존 모델은 텍스트 혹은 음악 영상에 특화되어 하나의 모델에서 같은 입력값만 이해하거나 결과값을 도출하게 되는데(LLM모델은 이미지를 인식하지 못했음) 멀티 모달은 마치 인간이 사과를 이해하는 방식이 다양한 것 처럼 다양한 양식의 데이터를 하나의 모델로 처리가 가능해 짐
이미지를 인식하고 그 이미지를 바탕으로 글을 쓴다 던지 소설을 바탕으로 그림 혹은 영상을 만들어냄
음성인식 기술과 비슷하게 작동 음성을 인식하여 임베딩된 단어와 매칭시킴
지금은 대부분 LLM모델이 멀티모달로 진화되어 있음 GPT가 이미지를 인식하고 관련 대화가 가능함
AI 산업
AI 산업은 관련 기술을 개발하거나 AI를 활용한 제품 및 서비스를 생산·유통·활용하는 등의 과정에서
가치를 창출하는 산업을 말함.
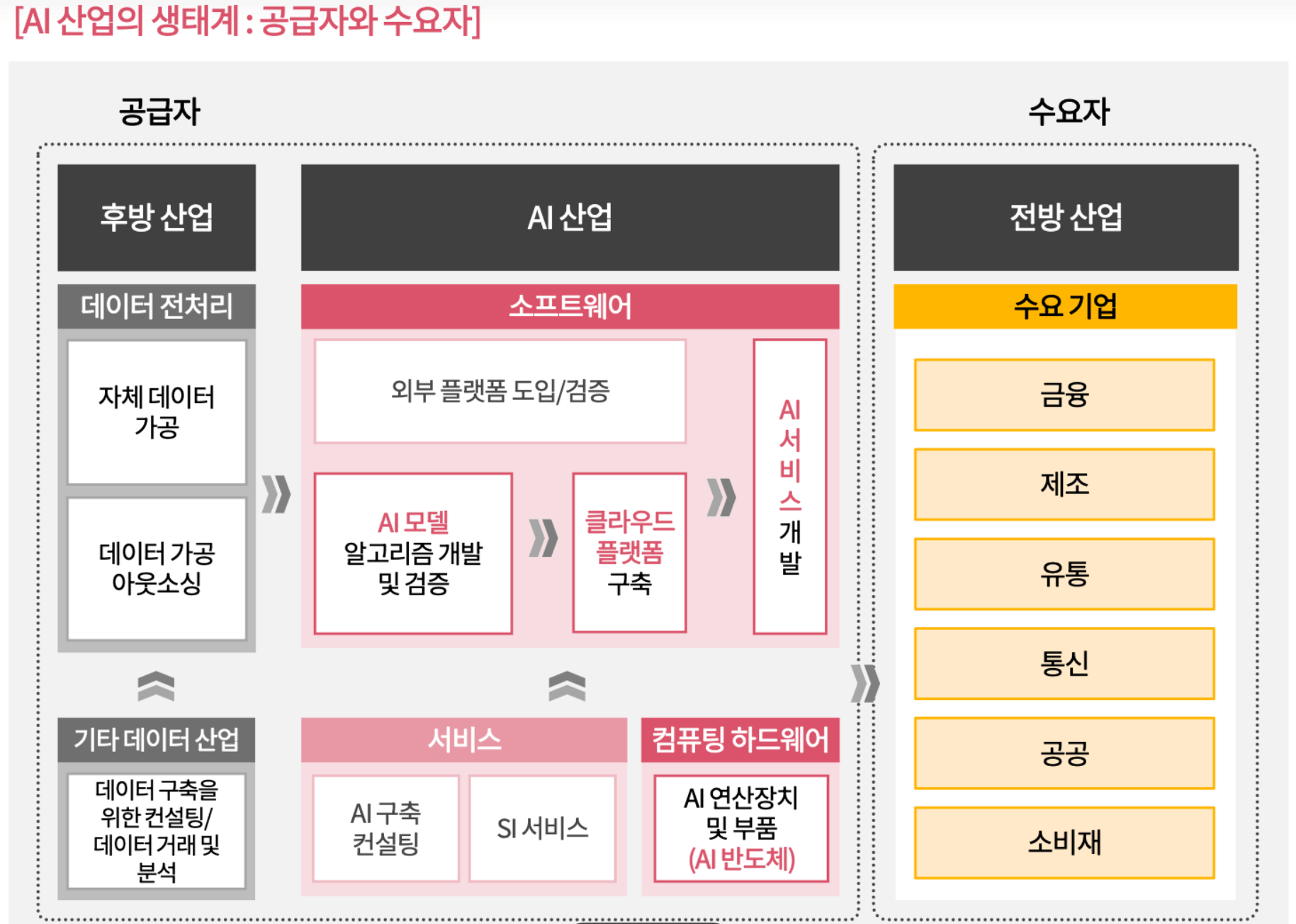
*후방산업: AI 학습 및 활용을 위한 데이터 수집, 구매, 구축 컨설팅, 분석 등과 연계된 생태계
*전방산업: AI를 활용하여 제품 및 서비스를 생산하고 제공하는 영역
현재까지 AI 산업에 있어서 주력은 공급자(AI 기술 관련 기업) 시장이었으나 향후에는 점차 수요자
(전방산업) 중심의 시장으로 변화될 것.
AI 비지니스 모델 구조
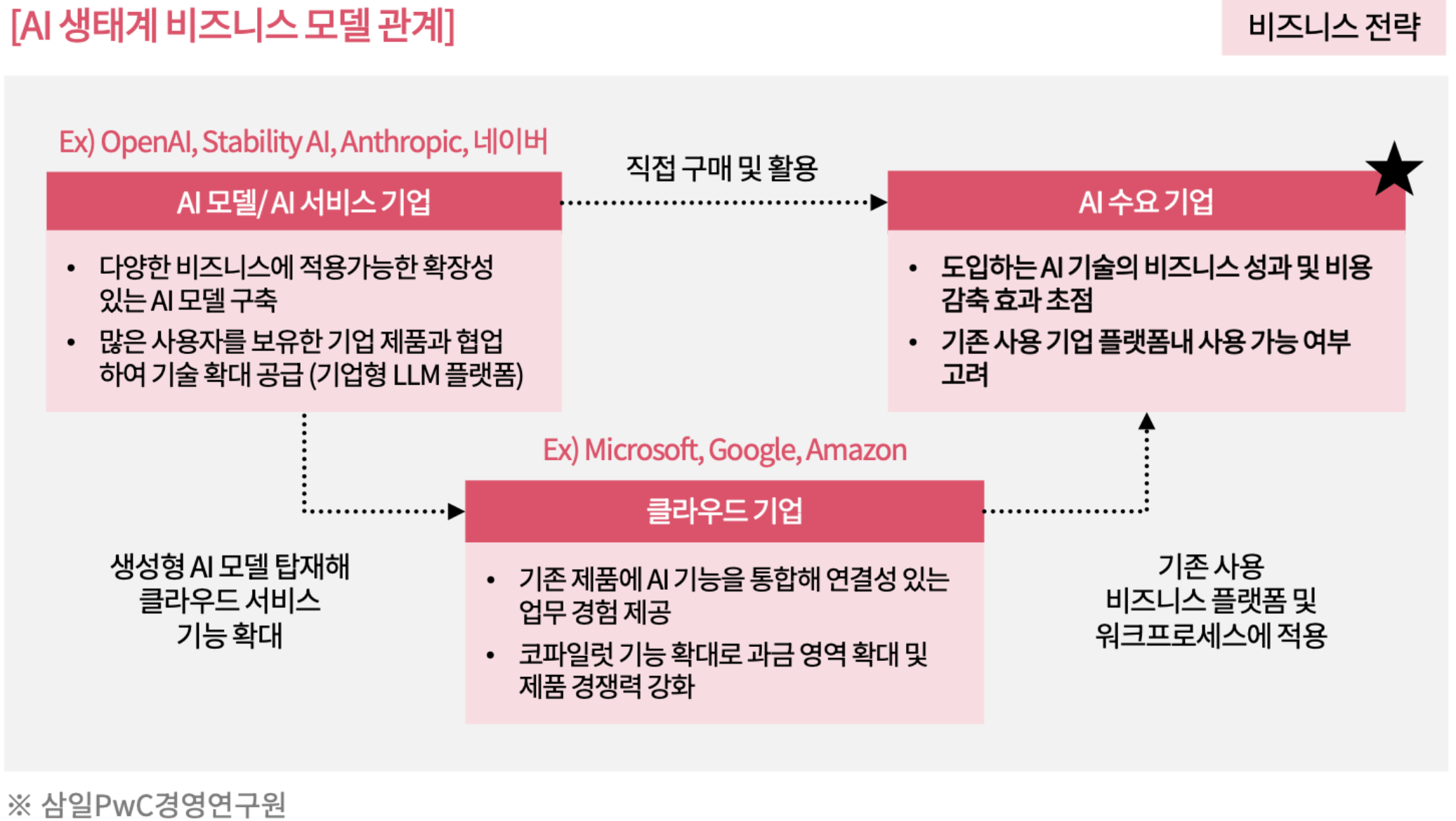
AI 비지니스는 AI를 직접 개발하여 서비스 하는 회사인 오픈 AI, 퍼플릭시티 등이 있고 AI를 구동할 수 있는 하드웨어를 제공하는 AI 클라우드센터(하이퍼 클라우드서비스)를 서비스 하는 마이크로소프트, 아마존웹서비스 등과 이것을 활용하여 애플리케이션을 만들어 서비스를 제공하는 대표적인 회사로 세일즈포스, 세일즈포스 등을 이용하여 회사의 비용을 절감하고 인력을 대체하거나 생산성을 향상 시키려 하는 AI 수요 기업으로 구분 할 수있음.
공급자 측면에서 AI비지니스 생태계
1.AI 데이터센터(마이크로소프트, AWS)
- 컴퓨팅 하드웨어(엔비디아, 하이닉스)
2. AI 모델 서비스 기업 (GPT, 퍼플릭시티)
3. AI 애플리케이션(세일즈포스 등)
* 기술력, 자금력등을 고려시 신규 진입장벽 순으로 1 > 2 > 3
1. AI 데이터센터(하이퍼클라우드 서비스)

AI 데이터 센터(하이퍼클라우드서비스)는 AI를 구동할 수 있는 하드웨어로 서버를 구축하여 AI를 제작 설계하는 회사에 사용료를 받고 임대하는 사업을 영위하는 회사. 대표적인 회사로 마이크로소프트, 아마존웹서비스, 구글 등이 있음.
일반 사용자가 마이크로소프트 '원드라이브'나 네이버 '마이데이터' 처럼 데이터센터를 통해 클라우드 서비스를 이용 하듯이 AI 개발 회사에서 AI를 개발하는데 있어 필요한 프로그램과 하드웨어 성능을 AI데이터 센터 서버에서 이용 함.
AI데이터 센터의 경우 한개 서버를 구성하는 데 약 1억~2억까지 소요 되며, 데이터 센터 건설 비용은 2.5MW기준 약 3,000억 정도가 소요 됨.(ChatGPT 같은 AI 서비스를 운영한다면?.. : 네이버블로그)
참고로 최근 한국에 세계최대 데이터센터를 구축한다고 화제가 되었는데, 3기가 와트 규모의 데이터 센터 구축에 약 50조원 투자 예정.(50조원 투자받아 韓에 데이터센터 지으려는 이 사람)
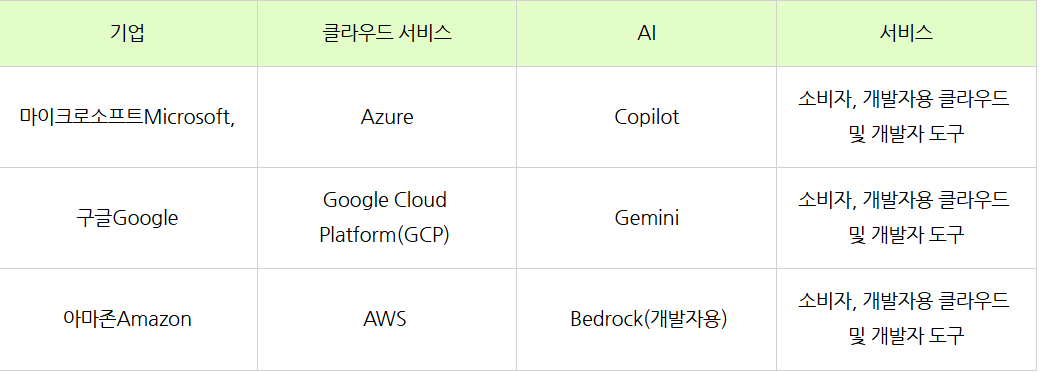
전형적인 자본집약형 산업으로 AI 서비스 회사들 혹은 소규모 AI 개발자들이 대규모 자금을 투입하여 필요한 모든 서버를 구축할 수 없기 때문에 빅테크 기업에서 대규모 자금을 투입하여 인프라를 구축하고 서비스를 제공.
예를 들어 소규모 사업장에 필요한 고객 콜센터를 운영하는 챗봇을 제작한다고 데이터 센터를 건설하면 너무 많은 초기 자본이 투입되니 aws 같은 회사의 인프라와 소프트 웨어를 이용하여 챗봇을 제작함
상기 표에 나와 있는 3개사에서 전세계 AI 데이터 센터의 대부분을 차지 하고 있음. AI 특성상 최초 개발에 이용한 데이터 센터를 지속 이용할 수밖에 없기 때문에 락인 효과가 강하고 한번 개발한 AI를 계속 사용하는 한 데이터 센터를 이용 해야하기 때문에 향후 빅테크 3개 회사가 전세계 AI 데이터 센터의 대부분을 과점하게 될것. 초기 투자 비용이 사라지고 어느 정도 시장이 안정되고 나면 AI 서비스 회사들 보다 경쟁에서 자유롭고 꾸준한 이익이 보장 되어 있다 할 수 있음.
- AI 데이터센터구성
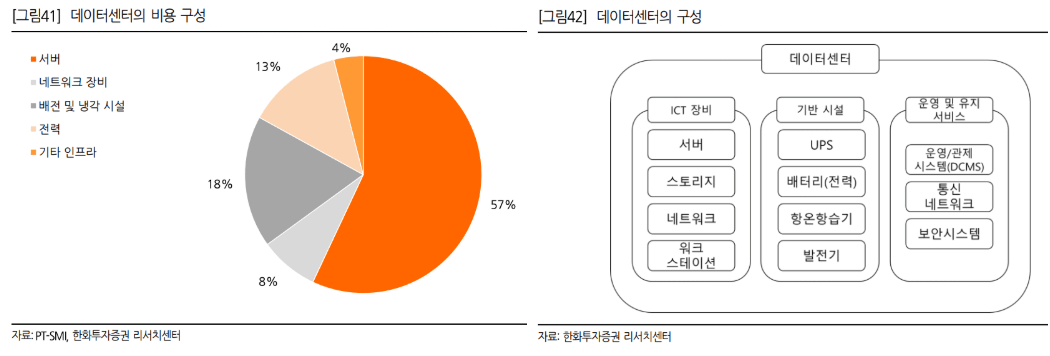
데이터센터는 서버, 네트워크장비, 배전 및 냉각시설, 전력, 기타 인프라로 구성이 되며, 그 중에서도 서버 장비에 가장 많은 비용이 소요됨.
서버 장비는 CPU, GPU, RAM, 스토리지(eSSD), 네트워크로 구성.
* 자세한 내용은 하기 구성요소 참조
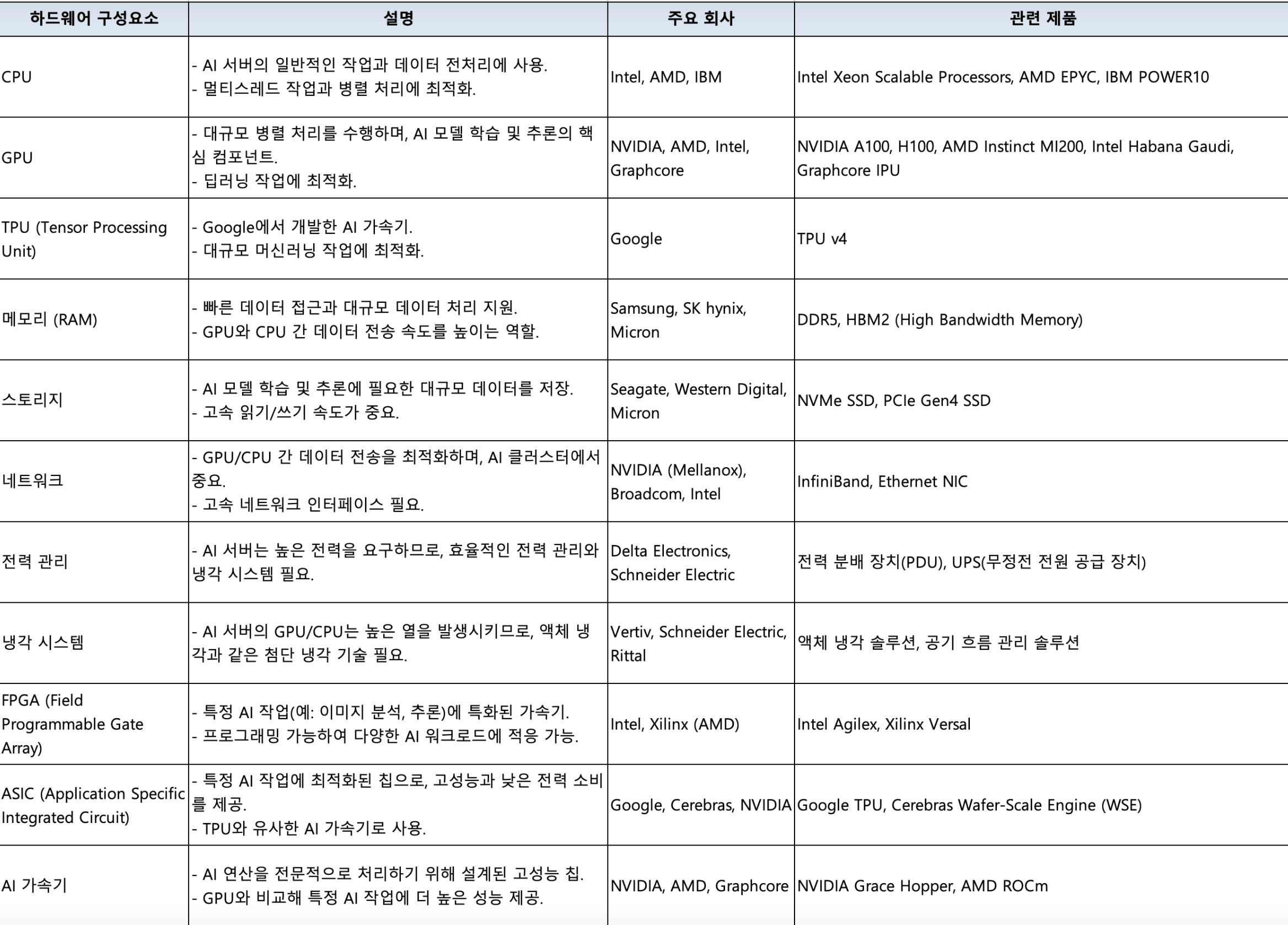
FPGA, ASIC, TPU 등 AI 가속기는 보통 하나의 서버에 중복으로 다 쓰지 않고 서버별로 목적에 맞추어 하나의 가속기가 추가됨.
* 데이터 센터 구축비용 추정(2.5mw, GPU 1만대 엔비디아 V100)
(ChatGPT 같은 AI 서비스를 운영한다면?.. : 네이버블로그)
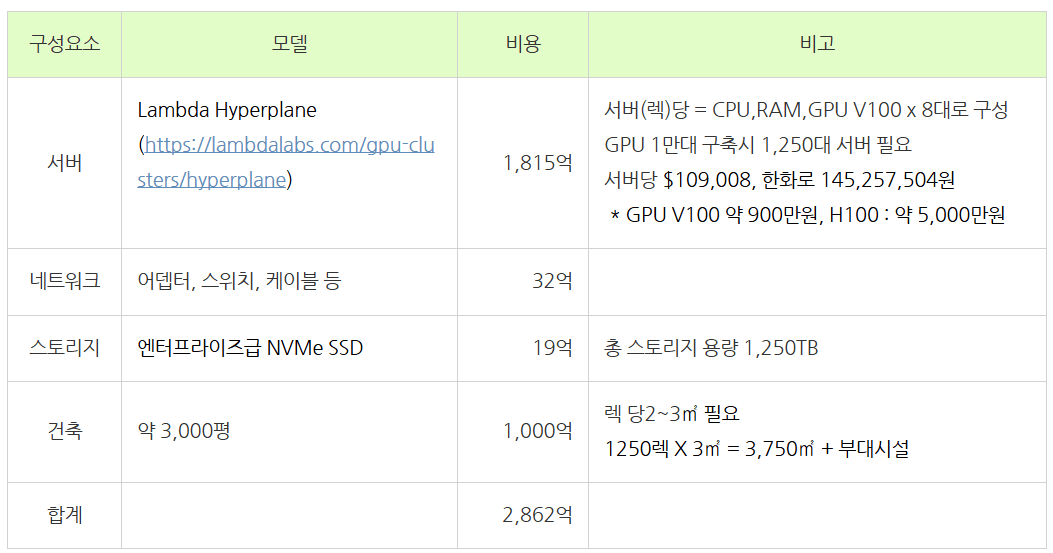
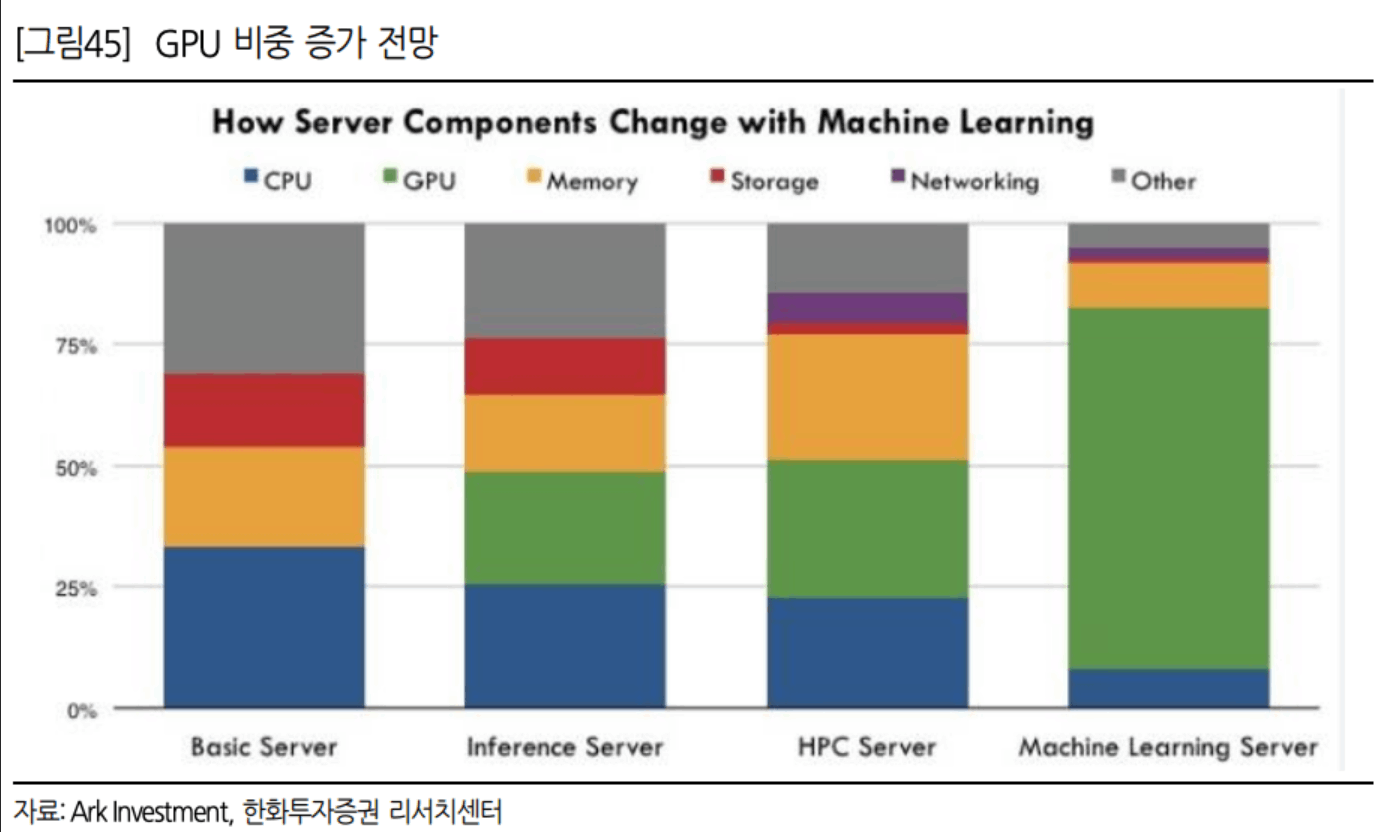
AI 데이터 센터의 경우 AI학습과 추론에 필요한 병렬, 행렬계산에 특화 되어 있는 GPU의 사용 비중이 압도적이며 비용 측면에서도 가장 큰 비중을 차지함.(최근에는 데이터센터의 전력 사용량 급증으로 인한 전력 부족 우려로 데이터센터 전력 및 배전 냉각시설에도 많은 비용이 들어감.)
일반적으로 한 데이터센터에는 GPU가 약 1만대 가량 설치되며, 엔비디아 H100의 현재 가격이 대당 약 5천만원 선으로 형성. 따라서 H100으로 1만 대를 구축할 경우, GPU 설치 비용만으로도 약 5천억 원의 예산이 소요.
- 시장전망
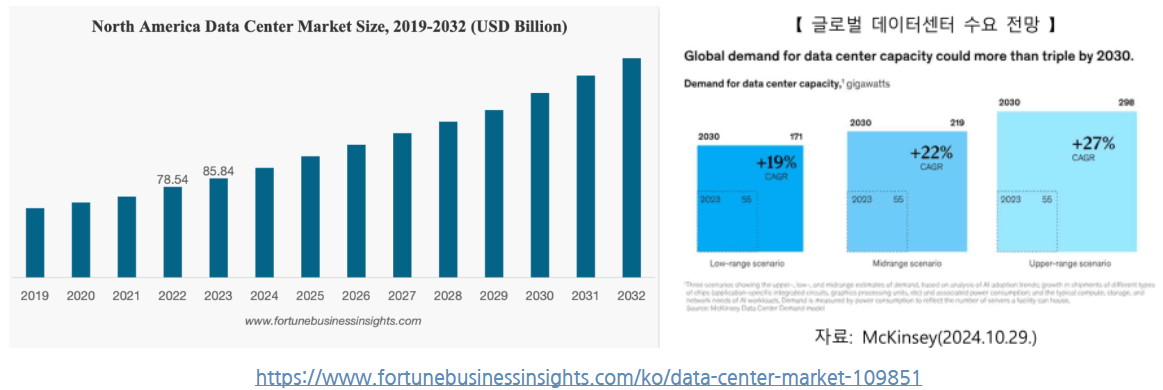
2023년 전 세계 데이터 센터 시장 규모는 2,192억 3천만 달러로 평가. 시장은 2024년 2,427억 2천만 달러에서 2032년까지 5,848억 6천만 달러로 성장하여 예측 기간 동안 CAGR 11.6%를 나타낼것.(하이퍼스케일 데이터센터 1,000곳 돌파··· 총 용량 4년마다 두 배)
생성 AI 모델, 특히 딥 러닝을 기반으로 하는 모델은 훈련과 간섭을 위해 상당한 컴퓨팅 리소스가 필요. 이로 인해 고성능 컴퓨팅 인프라에 대한 수요가 증가하고 더욱 강력한 데이터 센터에 대한 필요성이 높아질 것.
AI 모델에는 훈련을 위한 대규모 데이터 세트가 필요한 경우가 많으며, 이를 위해서는 강력한 데이터 저장 및 관리 솔루션이 필요.
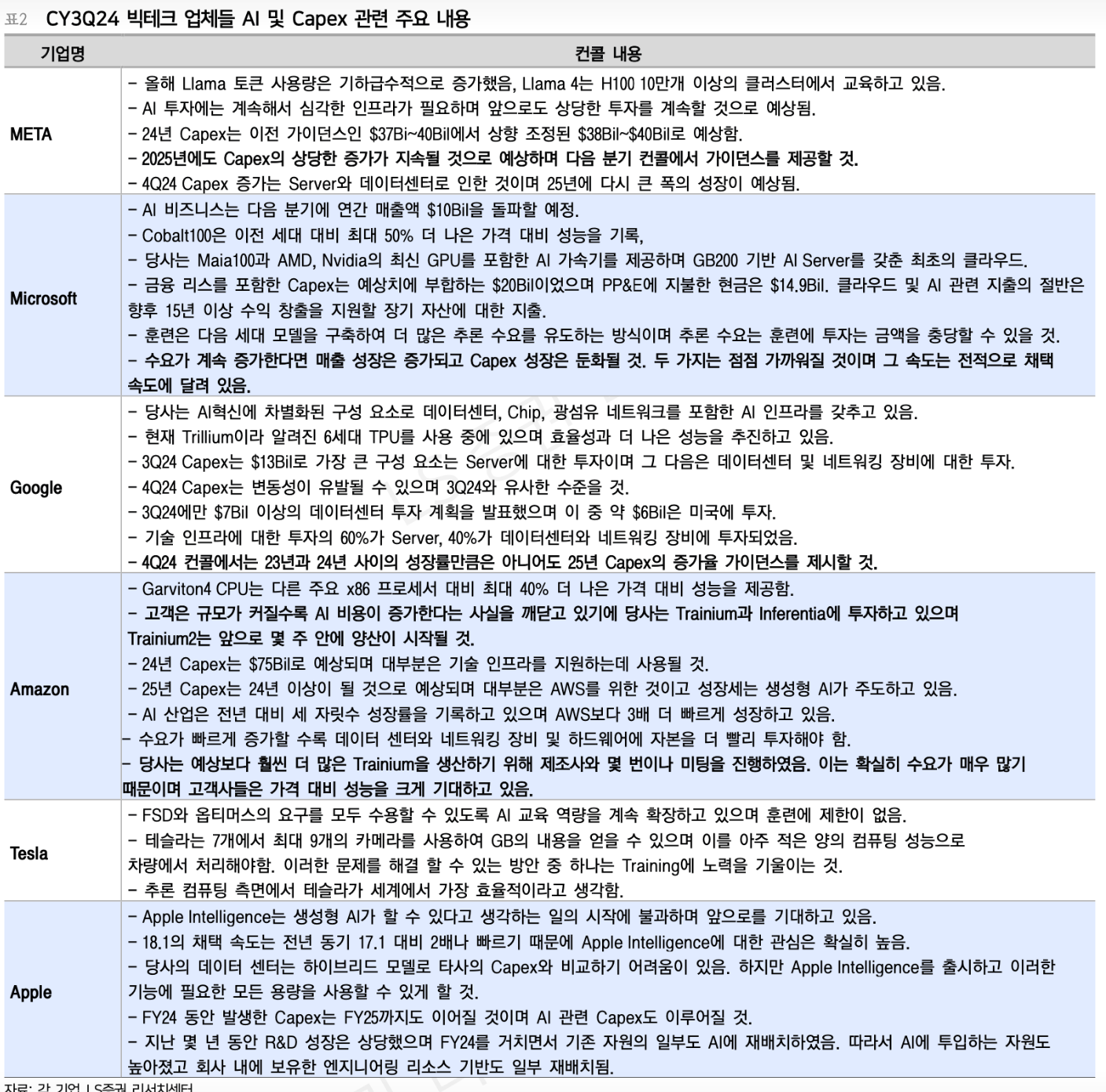
딥시크 기술의 등장으로 추론 과정에서 메모리 사용량이 크게 줄어(입력데이터를 분석하여 총 6,710억개의 파라미터에서 토큰 처리시 필요한 부분 370억개만 활성화 되게 설계하여 추론시 최적화를 이룸) 고성능 GPU 의존도가 다소 낮아질 수는 있으나(파라미터를 적게 쓰면 쓸수록 연산량이 줄어들기 때문에 그 만큼 하드웨어 소모를 줄일 수 있음), 영상·광고·법률 서비스 등 다양한 분야에서 AI 에이전트 개발이 가속화될 것으로 예상되므로, 전반적인 GPU 수요는 여전히 높은 수준을 유지할 것으로 전망.
미국 빅테크사는 딥시크 출시 이후에도 CAPEX 투자를 줄이지 않고 오히려 늘리고 있으며, 딥시크의 최초 개발국인 중국 또한 2025년 CAPEX 집행을 예년 대비 대폭 확대할 계획(Telegram: Contact @EMchina
)이기 때문에 향후 데이터센터 투자는 지속될 것으로 예상 됨.
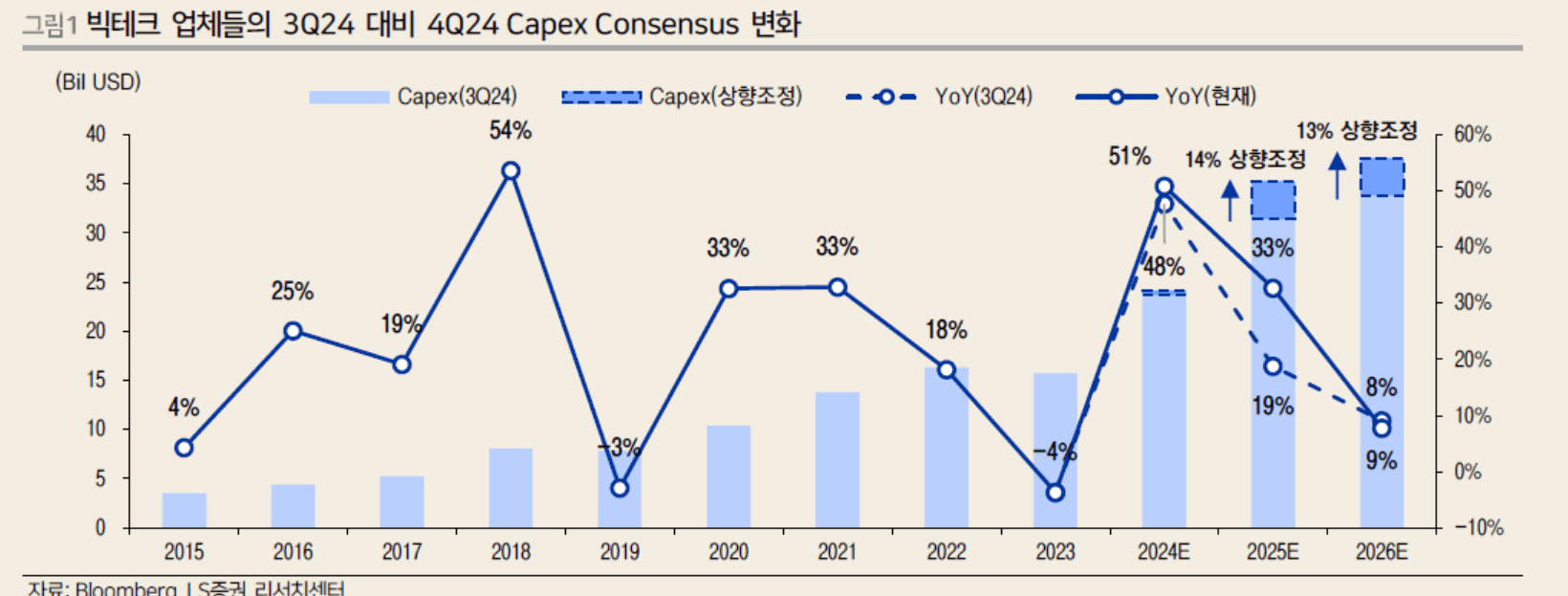
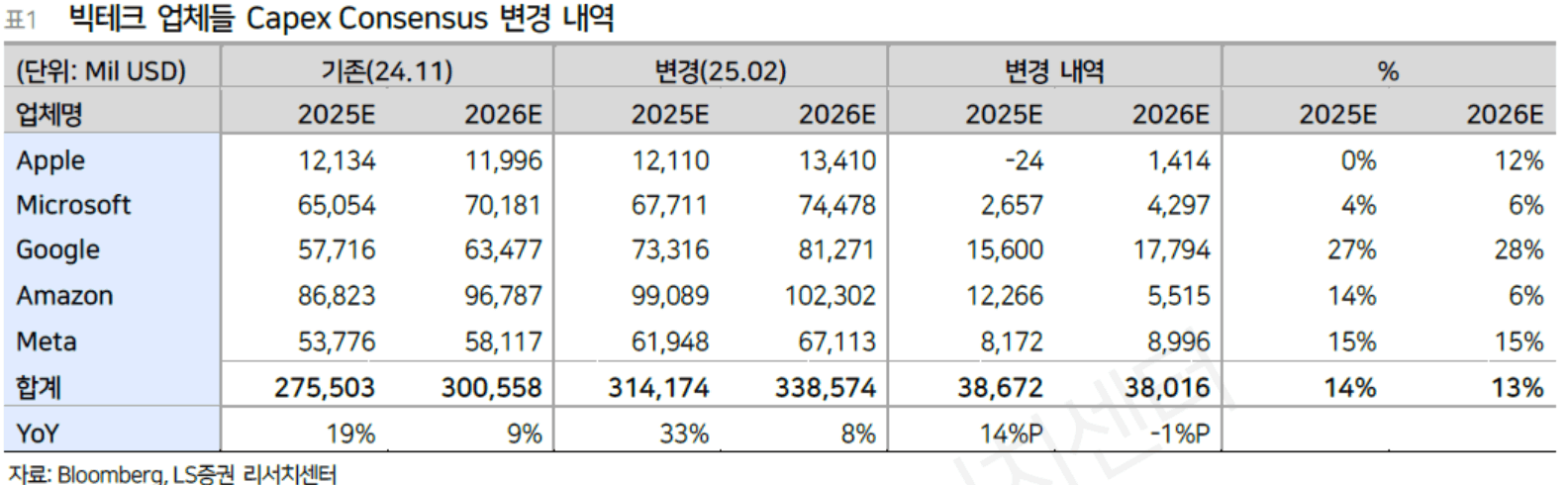
하지만 딥시크의 출현으로 AI초기에 예상했던 CAPEX투자가 향후에도 지속될 수 있을지는 의문이 있고 딥시크 출시 전 최초 예상했던 규모보다는 줄어들 가능성도 존재함.
또한 AI 서비스 기업들은 하드웨어가 전체 비용에서 가장 큰 비중을 차지한다는 점에서, 파라미터 수를 줄이면서도 성능을 유지할 수 있는 다양한 최적화 기법을 활발히 연구·개발하고 있음. 이에 따라 시간이 지날수록 하드웨어 의존도가 점차 감소할 것으로 예상해 볼 수 있음.(세이지메이커 하이퍼포드와 트레이니엄 칩의 조화, 파라미터 효율적 미세조정으로 LLM 학습 비용 최대 50%↓, 시간 70%↓줄인다)
2. AI 모델 서비스 기업
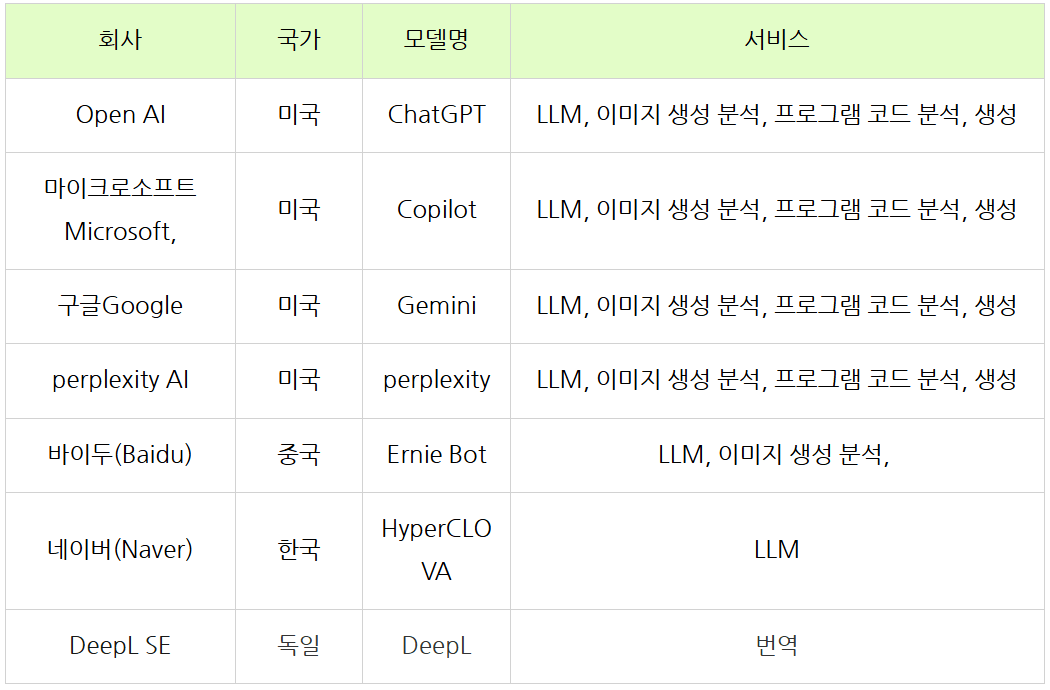
초기에는 언어 모델만 서비스하다 최근에 이미지 분석 생성, 프로그램 코드 생성 까지 점점 진화하고 있음. 종국엔 인간의 감정을 이해하고 좀더 창의적인 활동을 할 수있는 인간과 유사한 수준의 지능을 가진 AGI (Artificial General Intelligence, 인공 일반 지능)가 될 것으로 보고 있음.
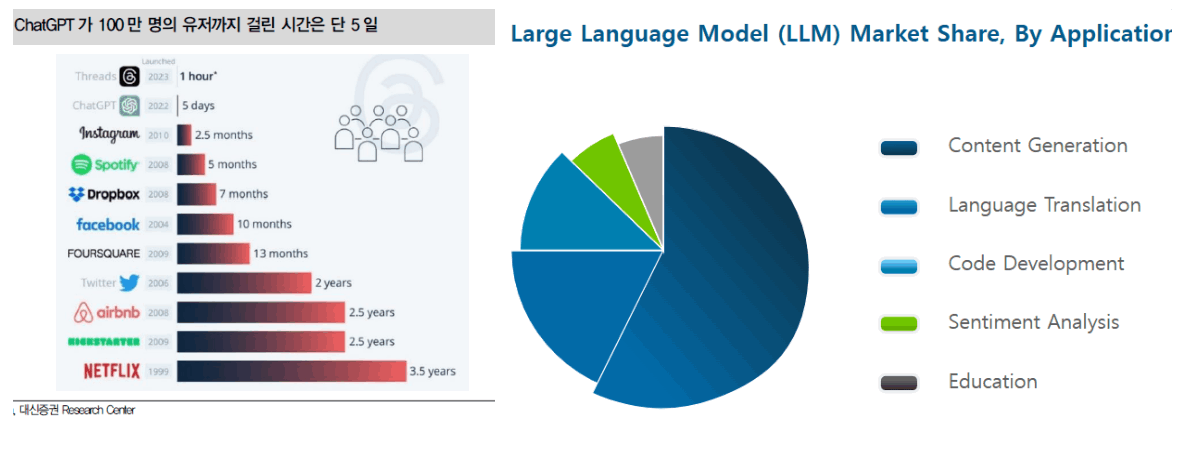
서비스 종류
언어 번역
여러 다른 언어의 문맥과 의미를 고려하여 번역의 정확성을 향상시킴 기업과 개인 모두 즉석 번역 기능을 사용하여 서로 다른 위치에 있는 사람들 간의 일상적인 커뮤니케이션을 더 쉽게 할 수 있게 됨. 운영 과정에서 LLM은 언어에 적응하여 번역 오류를 줄이고 대상 고객을 위한 언어의 로컬라이제이션 프로세스를 더욱 개선할 수 있음.
코드 개발
지루한 코드 작성 작업을 없애고 코드를 작성할 수 있는 자동화된 방식으로 코더와 개발자를 지원. 기본적으로 프로그래밍 언어의 구성을 이해하고 관련 지원을 제공하여 개발 프로세스를 빠르게 진행할 수 있도록 함. 이 애플리케이션은 주로 코딩 시 실수로 인한 시간 낭비를 없애고 코드 작업의 효율성을 향상시키는 데 도움.
감정 분석
텍스트를 분석하여 긍정, 부정, 중립 또는 중간 수준의 차이 등 텍스트의 핵심에 있는 감성을 감지. 이는 기업이 고객 반응, 사회학적 통찰력, 상업적 동기를 파악하는 데 필수적. 기업이 감정 분석을 통해 여론으로 전략을 뒷받침하는 데 도움.
교육 분야: 교육 분야에서 LLM은 교수법을 맞춤화하고, 학습 콘텐츠 전달을 개선하며, 평가 속도를 높이고, 튜터링 시스템을 통해 피드백을 제공하는 데 도움. 학습자는 훨씬 더 사용자 친화적인 방식으로 정보를 찾을 수 있고 교수자는 학습하는 시스템을 개발하는 데 도움. 이 기술의 적용은 e-러닝과 원격 학습을 향상 시킴.
시장전망
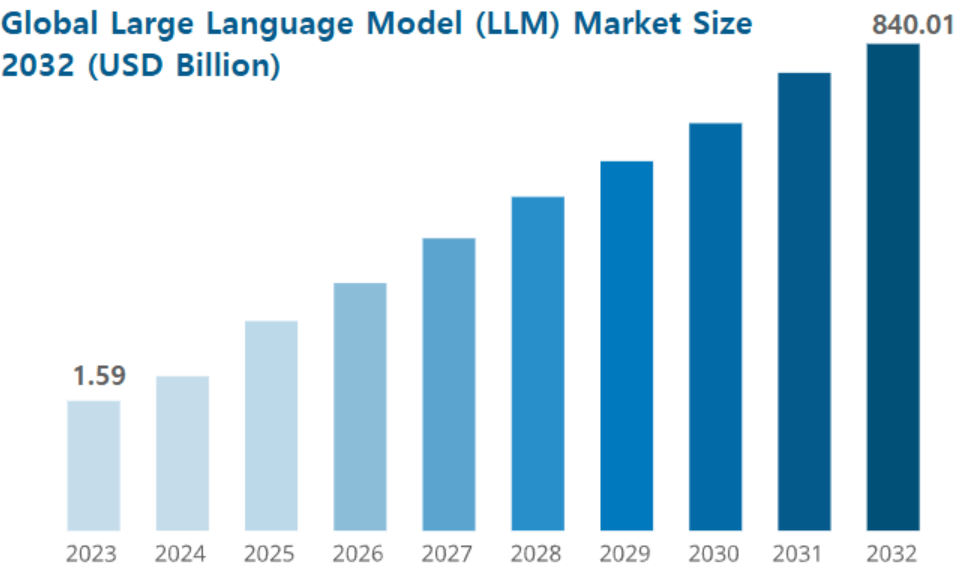
대규모 언어 모델(LLM) 시장 규모는 2023년 약 15억 9,000만 달러로 평가되었으며, 2023년부터 2032년까지 약 79.8%의 연평균 성장률(CAGR)로 성장하여 2032년에는 8,401억 달러에 달할 것으로 예상
3. AI 소프트웨어(응용 애플리케이션)
LLM 사업자가 제공하는 파운데이션 모델을 바탕으로 제작하는 여러 종류의 응용 애플리케이션
* 파운데이션 모델
LLM 사업자들이 제공하는 일종의 반제품 형태의 LLM(API형태로 제공).
파운데이션 모델을 바탕으로 챗봇이나 회사에 필요한 혹은 소비자가 필요한 여러 애플리케이션을 제작.
예를 들어 의료관련 어플리케이션 회사에서는 LLM 사업자에게서 파운데이션 모델을 구입. 완성된 언어 모델을 바탕으로 의료 임상관련 데이터만 학습 시키면 빠르게 의료 관련 어플리케이션을 제작할 수 있게 됨.
헬스케어 생명공학분야
영상진단 및 질병예측
AI 기반 의료 영상은 사람의 눈으로 식별하기 힘든 미세한 변화와 패턴을 감지해 진단의 정확성과 효율성을 높임.
- Arterys 사례
Arterys는 방대한 심장 MRI 데이터를 클라우드에 축적하고 딥 러닝으로 진단을 지원하는 소프트웨어를 개발해 2017년 클라우드 기반 딥 러닝에 대한 세계 최초의 미국 식품의약국(Food and Drug Administration, FDA) 승인을 받음. 현재 골절, 기흉, 폐 결절, 뇌졸중, 유방암 감지 등 다양한 영역에서 AI 기반 영상 진단 소프트웨어를 제공하고 있으며, Arterys가 개발한 3D 및 4D MRI 영상은 심장의 혈류를 사실적이고 입체적으로 시각화해 효과적이고 정확한 영상 진단을 지원하고 있음.
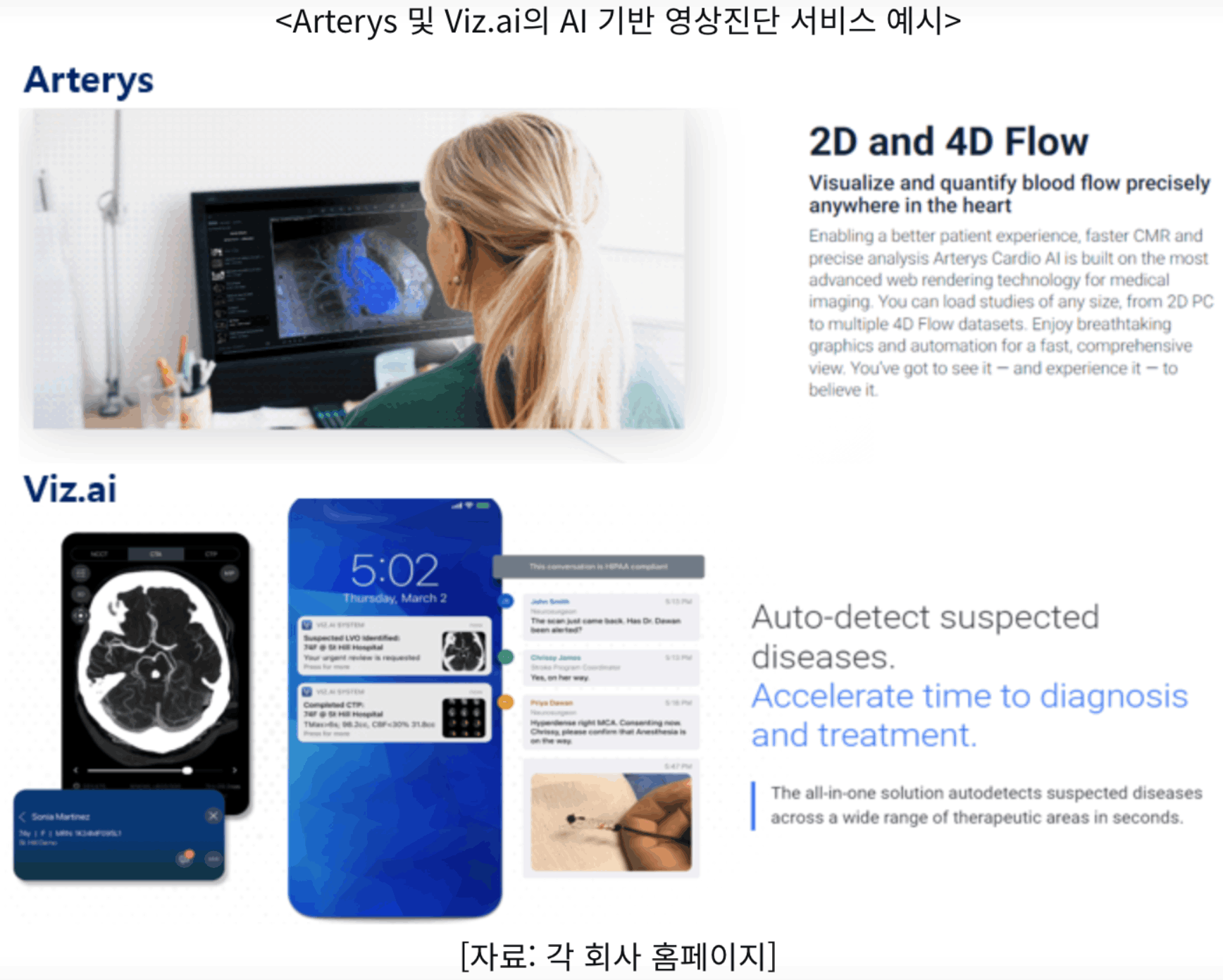
- Viz.ai 사례
CT 촬영, 심전도, 심장초음파 등을 포함한 의료 영상 데이터를 분석해 뇌졸중, 동맥류, 폐색전증과 같은 특정 질병이 의심되는 환자를 식별해 의사에게 초기 징후를 경고 함. 뇌 CT 촬영으로부터 몇 초 이내에 뇌졸중 여부를 자동 감지해 의심 환자를 식별한 뒤 즉시 뇌졸중 전문의의 휴대 전화로 알림을 보내고, 이를 통해 의사는 위험 환자군을 사전에 예측하고 진단 속도를 단축해 신속한 치료를 시행 함. 동 소프트웨어는 현재 전 세계 1,400개 이상의 병원에서 활용 중임
신약개발
- 후보물질 발굴 : 분자설계 및 최적화, 바이오마커 발견, 구조활성관게(SAR) 모델링.
고전적 방법으로는 수천~수만 개 물질을 일일이 실험해야 하지만, AI 알고리즘(머신러닝·딥러닝)을 활용해 분자 특성과 약리학적 프로파일을 사전에 예측. → 초기 실험 횟수 감소 → 시간·비용 절감.
컴퓨터 시뮬레이션을 통해(인실리코 테스트강화) 약물의 약리작용, 부작용 등을 예측하여 실험실(웨트랩) 단계 진입 물질 수를 줄임.
글로벌 컨설팅 회사 Deloitte의 2019년 보고서에 따르면 신약 개발 프로세스는 평균 12년이 걸리고 약 26억 달러의 비용이 소요됨. 신약 개발 과정에 AI를 활용하면 약물 발굴 시간을 15배나 단축할 수 있고 신약 개발 비용을 최대 70%까지 절감할 수 있음.
- 임상개발 : 시험설계, 시험 실기기관 선정, 대상자모집, 데이터평가, 독성 예측 및 위험 모니터링, 모니터링 및 약물 순응도, 실제증거(RWE)분석.
전자의무기록(EMR) 또는 데이터베이스 분석을 통해 임상시험 대상 환자를 빠르게 모집하고, 조건에 맞는 환자만 빠르개 선별. 원격 모니터링 장치, 모바일 앱, 웨어러블 기기를 활용해 임상 환자가 병원을 자주 방문하지 않아도 참여 할 수 있도록 하여 임상시험 운영비(교통비, 인력 비용, 시설 비용)를 절감하게 됨.
클라우드·AI 분석 툴을 사용해 임상 데이터를 자동 수집·정제·분석함으로써, 모니터링 인력이나 중간 분석에 드는 시간을 단축.
- Recursion Pharmaceuticals 사례
희귀질환 분야 약물 개발에 중점을 두고 있으며 치료에 사용되는 새로운 약물 후보 추출, 약물의 작용 메커니즘, 잠재적 독성 등을 밝혀내는 데 AI 기술을 활용 하고 있음.
세포 관련 대규모 이미지 데이터와 슈퍼컴퓨터, 기계 학습, 자동화된 로봇 플랫폼은 매주 수백만 건의 실험 수행을 가능하도록 하며 새로운 약물 개발에 사용 함.
2018년에 FDA로부터 AI를 활용한 뇌 해면상 혈관 기형(Cerebral Cavernous Malformation) 치료 물질 임상 1상 시험계획에 대한 승인.

- Atomwise 사례
Atomwise는 3조 개 이상의 합성 가능한 화합물이 포함된 라이브러리를 보유하고 있으며 딥러닝 기반 신약 개발 플랫폼 AtomNet의 스크리닝 과정은 저분자의 생물학적 활성을 예측하고 새로운 후보 화합물의 유효성을 신속, 정확하게 추정 함.
기존의 약물 스크리닝은 몇 달 이상 소요되기도 하나 AtomNet은 하루에 100만 개의 화합물을 스크리닝 가능. AtomNet은 임상 시험 전 후보 화합물의 독성, 부작용 및 잠재적 효과를 예측해 약물 발견의 초기 단계를 간소화하고 의약품 개발 비용을 줄이는 데 기여하고 있음.
건강관리 및 원격의료
- Noom 사례
31억 건의 코칭 데이터에 기반한 인공지능 플랫폼과 심리학자, 영양사, 운동 생리학자 등으로 구성된 라이프스타일 코치진이 사용자 맞춤형 식이요법 등을 제안하며 이용자들의 식습관 변화 유도 함. 370만 개의 음식 단위 데이터베이스, 수천 개의 건강한 레시피, 체중, 운동, 혈압 등 임상 정보 기록 기능 등을 바탕으로 비만, 제2형 당뇨병, 고혈압 등 다양한 질환을 관리하고 개인의 건강 상태에 맞춤화된 프로그램을 제공.

- Youper 사례
AI 챗봇 기반의 심리상담 서비스를 제공하며 인지행동치료(CBT) 기법을 통해 사용자의 기분과 수면 패턴을 개선하고 우울증과 불안 증상을 경감시키기 위한 방법을 추천. 앱을 통해 자신의 기분과 정신 건강 상태를 체크할 수 있고, 심리학과 AI를 결합한 알고리즘은 사용자의 정서적 요구를 이해하고 자연스러운 대화를 이끌어가며 감정 조절 케어 하고 있음. 앱 사용자 4500명을 대상으로 한 실험에서 앱 사용 2주 뒤부터 불안 증상이 24%, 우울증이 19% 감소.
원격 의료 서비스와 결합해 전문가를 통한 온라인 치료와 처방 약의 배송 서비스도 제공.

시장전망
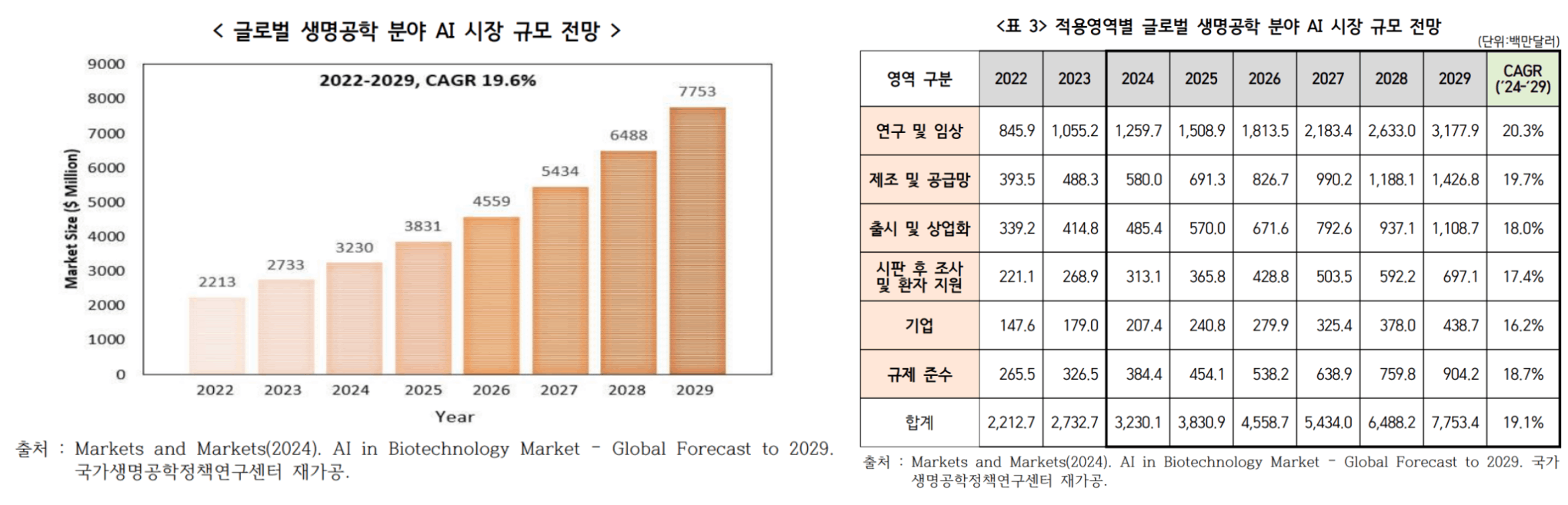
글로벌 생명공학 분야 AI 시장은 2024년 3,230백만 달러에서 연평균성장률 19.1%로 증가하여 2029년에는 7,753백만 달러에 도달할 것으로 전망
의료 분야에 AI 보급되면 유전자 정보, 디지털 헬스 데이터 등이 축적됨에 따라, 개인 맞춤형 의료가 보편화 됨. 또한 머신러닝과 합성생물학을 결합해 특정 상황에서 동작하는 맞춤형 생체시스템을 설계하거나, 나노입자·세포치료의 특성을 예측·최적화가 가능해질 것.
영상진단
과거 인간에 의존한 영상진단의 경우 진단의의 컨디션과 외부 환경에 따라 진단 결과가 다르고 부정확하게 나오는 경우가 있었음. 진단의 부정확 함으로 인한 의료손실을 AI를 도입을 통해 좀더 정확하고 일관된 진단을 확보하게 됨. 향후 더 많은 데이터가 축적 되면서 지속적인 학습을 통해 더욱 정교한 진단이 가능해 질 것으로 보고 있음.
시장조사기관 GlobeNewswire에 의하면 AI 의료 영상 시장 규모는 2022년부터 연평균 34.3% 성장해 2029년에는 275억2000만 달러에 이를 것으로 예상.
신약개발
과거 제약회사는 신약 개발을 위해 수많은 분자 구조를 일일이 실험실에서 실험을 반복 함.
이러한 방식은 비용과 시간이 막대하게 들었으나, 최근에는 딥러닝을 비롯한 AI 기술을 활용한 가상실험 기법을 이용하여 약물의 약효와 독성 등을 사전에 예측함으로써, 불필요한 실험 횟수를 크게 줄일 수 있게 됨.
이로써 연구개발 비용과 기간을 단축해, 제약회사들은 훨씬 빠르게 신약 후보물질을 발굴하고 임상 시험 단계로 진입하게 되어 향후 각종 질병에 대응하여 신약 개발이 더욱 빠르게 이루어 질것으로 예상됨.
그랜드뷰리서치(Grand View Research)에 따르면 2022년 전 세계 신약 개발 AI 시장 규모는 약 11억 달러이며 2023년부터 2030년까지 30% 성장할 것으로 예상.
정신건강
정신 건강 진단의 경우 우울증 및 불안장애 진단에 있어 AI 기반 시스템의 정확도가 90%를 넘어서며, 의료진 부족 문제 해결의 열쇠로 주목받고 있음. 정신과 의사를 만나서 상담하는 것 보다 우울하거나 힘들때 AI와 즉각적인 대화를 하는 것이 치료효과를 더 빠르게 높일 수 있음.
2022년 글로벌 디지털 정신 건강 케어 시장 규모는 195억 달러로 평가되며 연평균 20.3% 성장해 2030년에는 711억 달러에 이를 것으로 예측 되고 있음.
영상 미디어 분야
- 하이퍼 리얼리즘 버추얼 휴먼(JTBC사례)
실제 사람의 얼굴 질감을 99%까지 구현하고 미묘한 표정과 근육의 움직임까지 그대로 재연하는 버추얼휴먼 ‘루이’의 제작 방식
Full HD 규격의 영상 자료들과 이미지 자료들을 취합하여 이미지 생성 AI인 GAN(Generative Adversarial Network, 생성적 대립 신경망) 기술을 적용하여 모델링을 구축
사망한 고 임윤택(가수)를 디지털 AI GAN신경망을 이용 딥러닝을 통해 버츄얼 휴먼으로 복원

- 멀티 모달 검색 플랫폼(SBS사례)
기존 키워드 기반 검색은 사용자가 정확한 단어나 문장을 입력해야만 관련된 결과를 얻을 수 있었으나, 벡터 임베딩 기반 검색은 입력된 데이터를 벡터로 변환하고, 유사한 벡터를 찾는 방식으로 동작하게 됨. 예를 들어, 영상에서 인물 검색을 하고자 할 때, 특정 인물의 이름이 아닌 해당 인물의 얼굴 특징을 벡터화해 비슷한 얼굴을 찾아내는 방식이라고 할 수 있음. 이는 방송 아카이브, 영화 데이터베이스 등에서 특정 배우가 등장하는 장면을 손쉽게 찾을 수 있게 함.
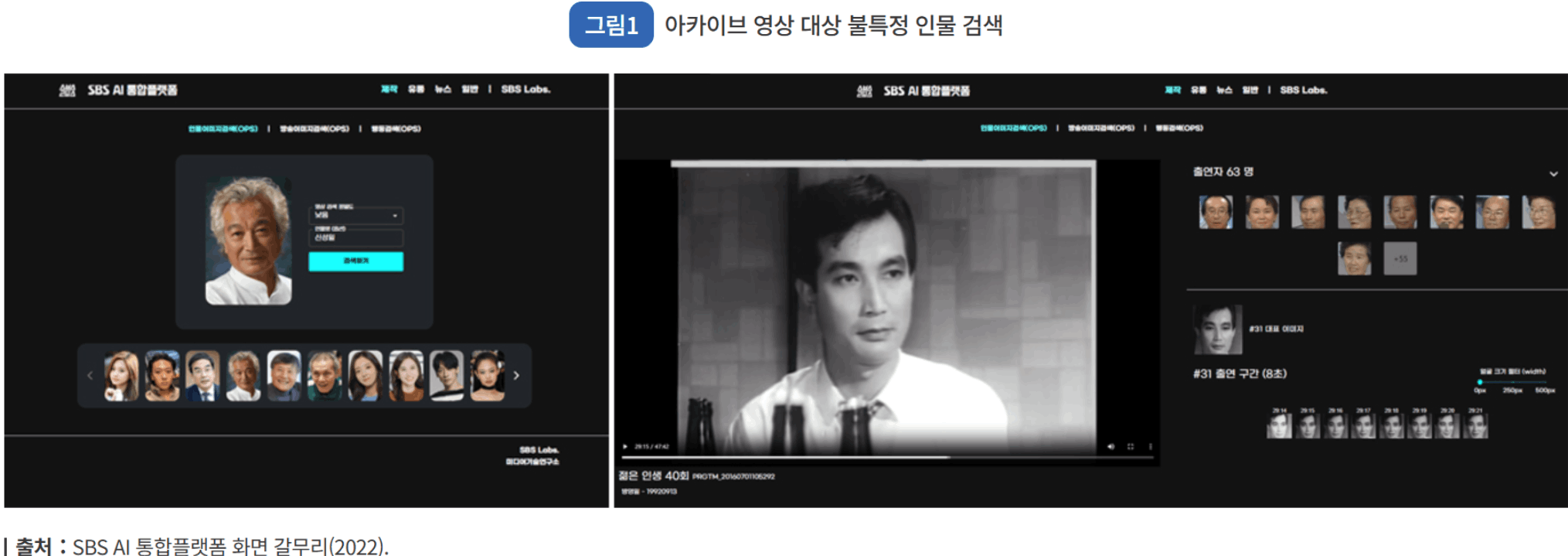
미디어 제작사는 수백에서 수천 시간에 달하는 촬영본을 제작하며, 방송된 영상들은 이미 수십만 시간에 이르는 분량으로 아카이브 시스템에 보관되고 있음. 이렇게 방대한 양의 영상 콘텐츠를 효율적으로 관리하려면 장면 단위의 메타데이터 생성과 관리가 필수적임.

- 자율형 미디어 에이전트(SBS사례)
실시간 TV 중심의 ‘제작→TV 송출’ 생태계가 비실시간 OTT 중심의 ‘제작→OTT 유통’ 생태계로 전환되면서, 지상파 방송사에서도 디지털 미디어 유통 업무가 확대.
IPTV 등 VOD 서비스를 위한 회차별 동영상 편집 및 메타데이터 관리 업무는 1일 20개 이내 정도로 제한되어 있지만, 유튜브 등의 OTT 플랫폼에 디지털 클립(쇼츠)을 제공하려면 수십 개의 채널에서 하루에 수백 개의 동영상을 편집하고 메타데이터를 입력해야 하므로, 비용과 인력 리소스가 대폭 투입될 수밖에 없음.
이를 해결하기 위해 AI를 활용, 관심 분야별로 디지털 콘텐츠를 선별하고 메타데이터를 자동으로 생성한 후, ott 채널에 자동 업로드하는 기능을 구현하고 저작권 정보 등을 자동으로 처리해 주는 기능을 구현.
자막 생성 에이전트(SBS사례)
ACR(Automatic Content Recognition) 기반의 자동 자막 생성 기술. 워터마크나 DNA 기술을 활용하여 클립 콘텐츠로부터 프로그램 회차 기준 상대 시간 정보를 획득한 후, 전체 회차 자막으로부터 구간 자막을 생성하는 기술.
일반적인 STT 기반의 한글 자막 생성은 수작업 보정이 필요하나, ACR 기반 한글 자막 생성은 이미 완성된 TV 클로즈드 캡션 자막의 일부를 활용하는 방식
- AI 영상 솔루션( ‘버티고 VVERTIGO', KBS 사례)
AI 편집 툴
K-POP 아이돌 그룹의 세로직캠 영상을 효율적으로 제작
기존에는 세로직캠 영상을 제작하려면 멤버 수에 맞게 카메라를 배치해야 했지만, 스튜디오 공간의 제한과 많은 방송용 카메라를 배치할 수 없는 물리적인 제약으로 인해 모든 멤버를 촬영하는 것이 현실적 불가능.
이에 AI 기술을 활용해 멤버별 직캠 촬영의 제약을 극복할 수 있는 새로운 방식모색. 그 결과, 8K 카메라로 무대 전체를 촬영한 뒤, AI 기술로 각 멤버를 자동 추적하여 개별 세로직캠을 생성하는 버티고 툴을 개발. 딥러닝 기반 인물인식 AI엔진 기술을 적용하여 움직이는 피사체를 자동으로 추적하여 키프레임을 생성.
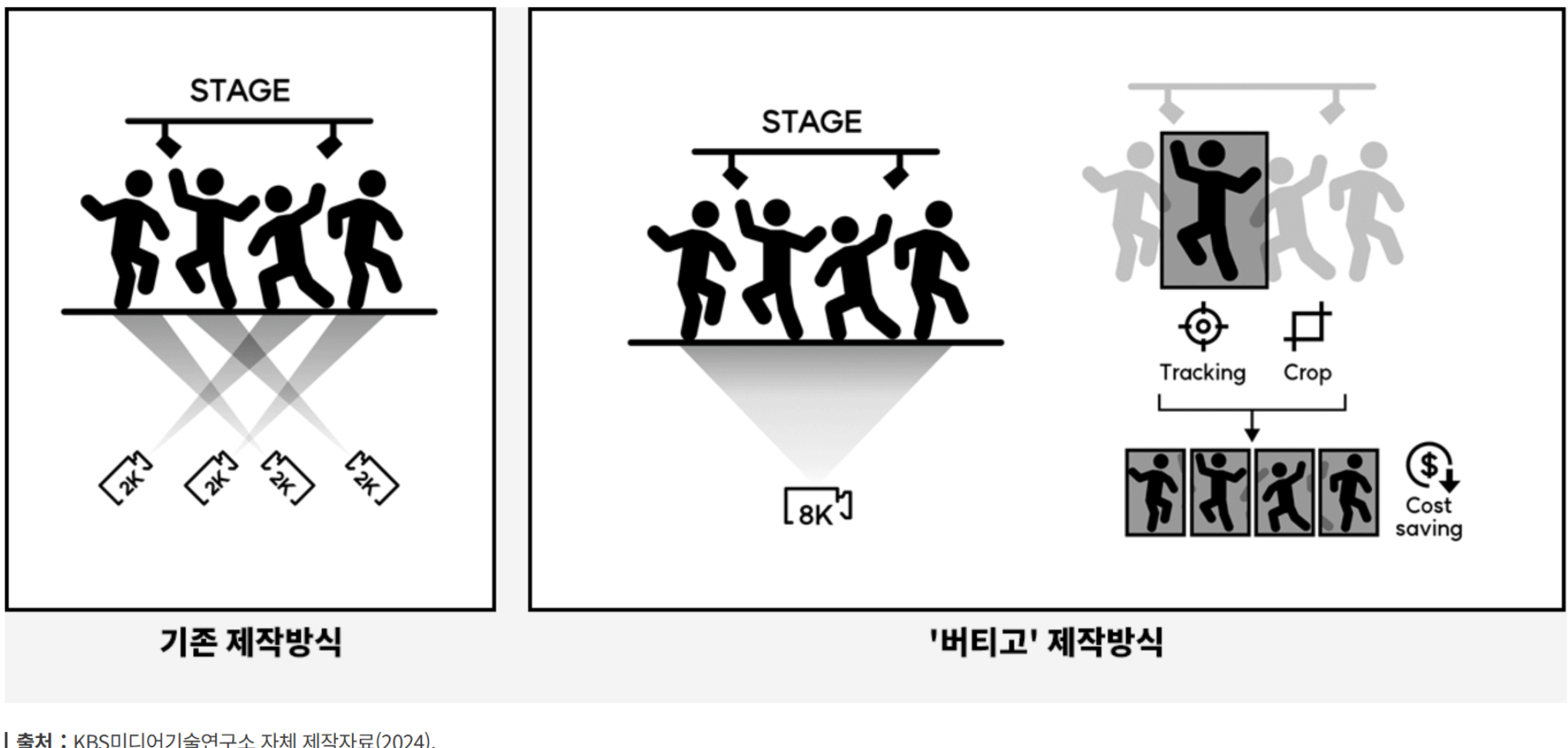
AI 영상 확장
‘버티고 비전’은 AI 기술을 활용해 무대 공간 영상을 확장하는 기술로, ‘버티고’ 엔진이 실제 무대 디자인을 자동으로 학습해 무대 세트 이미지만으로도 무대를 180도 전체로 확장

시장전망
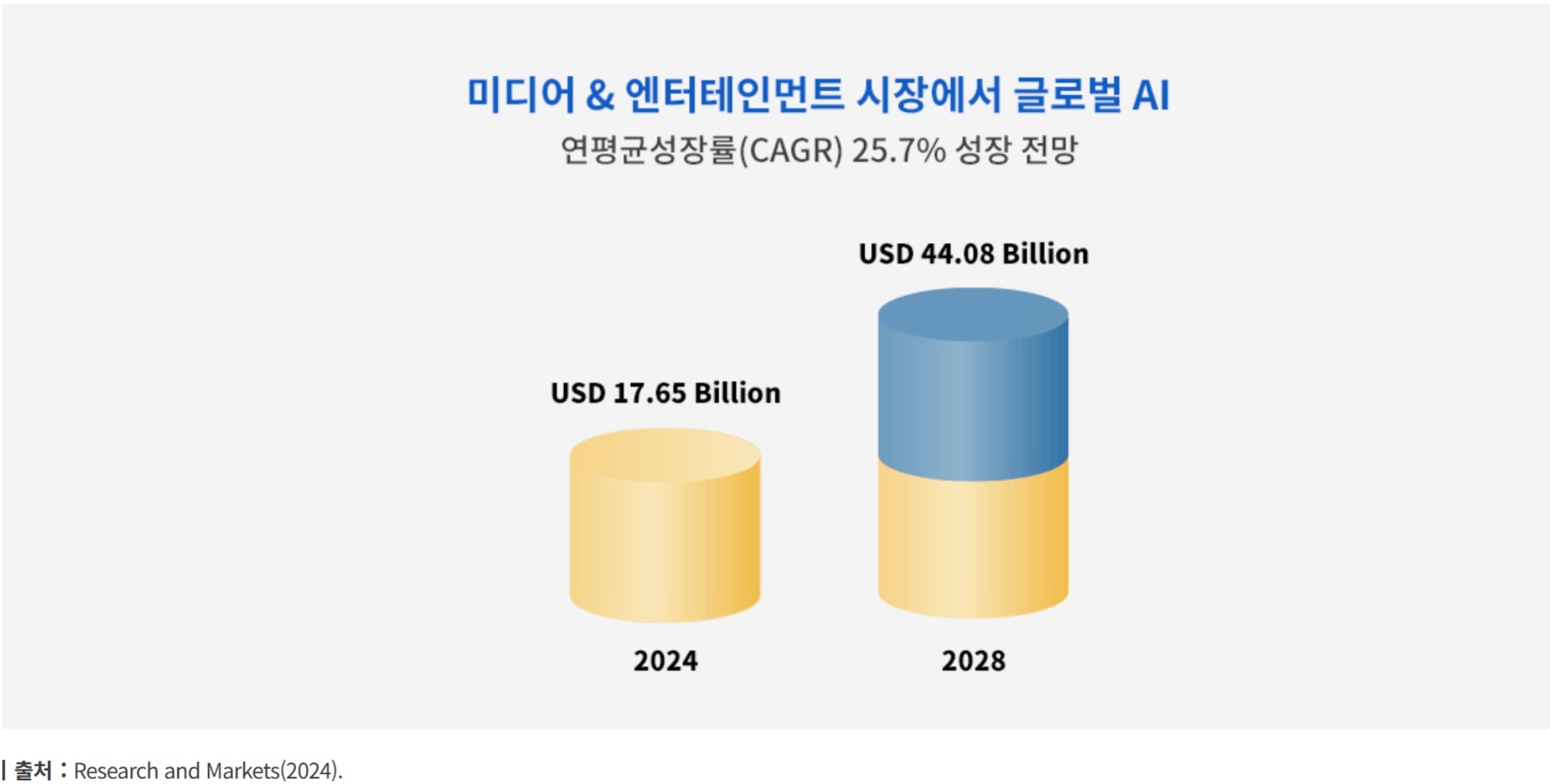
리서치 앤 마켓(Research and Markets) 자료에 따르면, 2028년까지 미디어&엔터테인먼트 시장에서 글로벌 AI 연평균성장률(Compound Annual Growth Rate, CAGR)은 2024년 대비 25.7% 성장할 것으로 전망.
AI 미디어 서비스 확대
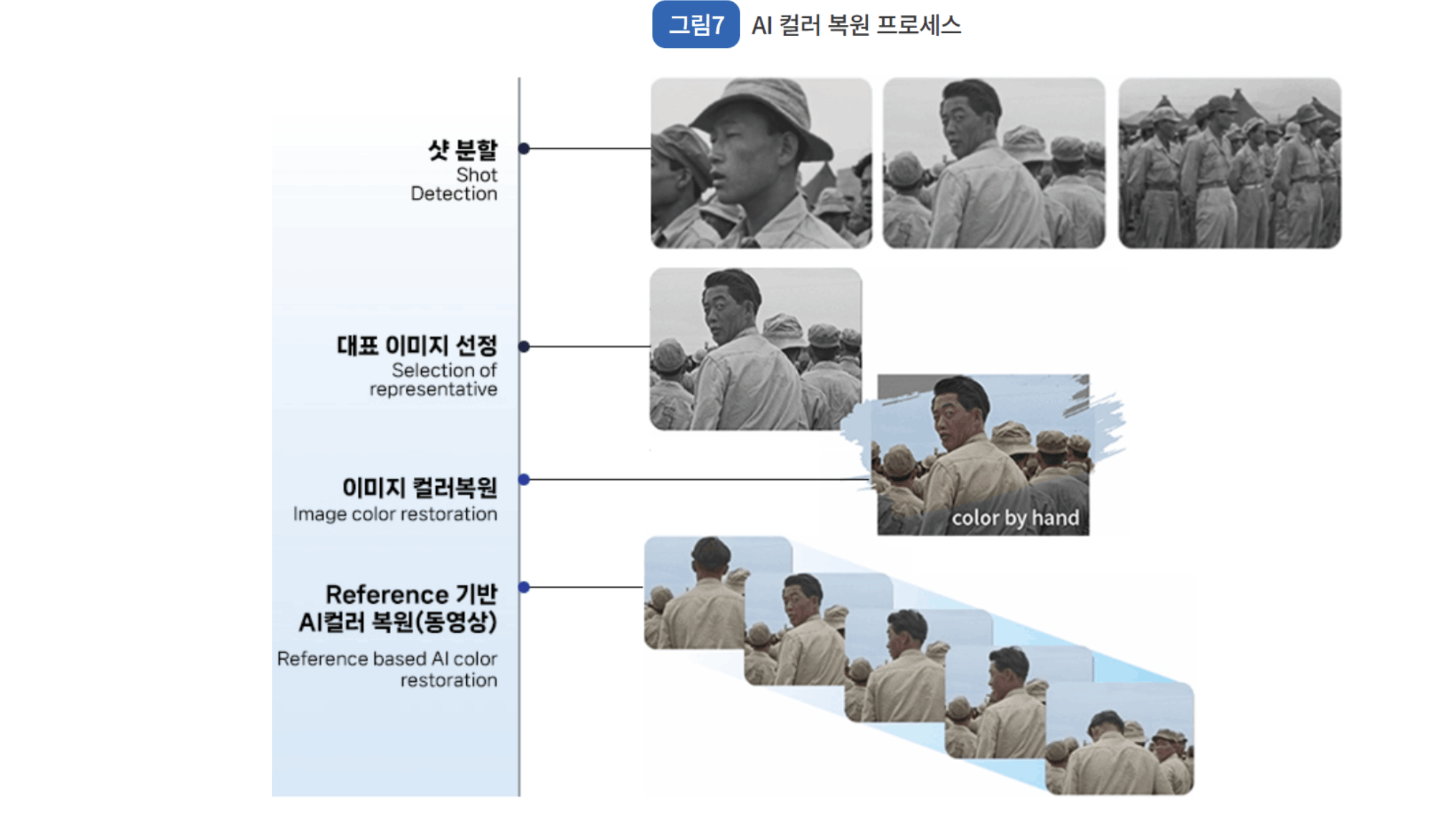
AI 컬러 복원
컬러 복원 기술은 영상에 색을 추가해 생생한 시청 경험과 역사적 가치를 증대시킬 수 있다. AI 엔진이 다양한 색상과 조명을 학습할수록 더욱 정밀한 컬러복원이 가능컬러 복원 과정에서 AI 기술을 활용해 많은 수작업을 대체했으며, 향후에도 컬러 복원 관련 AI 기술을 지속적으로 고도화해 나갈 계획
AI 스토리보드 서비스
콘텐츠 제작 과정을 자동화하기 위한 핵심 기술로, 생성형 AI를 활용하여 프롬프트 기반으로 스토리보드를 자동으로 생성하는 기술영화 제작 등 제작호흡이 긴 분야에서 사용되는 정교한 프리비즈(사전 시각화) 기술이 일일드라마나 웹예능 등 호흡이 짧은 콘텐츠 분야로 확산되는 계기가 될 수 있음. 이를 통해 보다 창의적인 콘텐츠 제작이 가능.
AI 자동 가편집 서비스
예능 콘텐츠(특히 스튜디오 예능) 제작의 경우, 멀티 카메라 설치와 조작에 따른 제약이 많고, 다수의 제작 인력이 필요함. 이러한 제약 상황을 해결하고, 효과적으로 K-POP 예능 콘텐츠를 제작하기 위해, AI 기반의 편집 및 제작이 가능한 ‘AI 버추얼 디렉터’ 개발.
‘AI 버추얼 디렉터’ 핵심 기술로는 멀티 고해상도 PTZ 카메라 설치 및 운영 최적화, 실시간 비디오 신호 트래킹, 오디오·비디오 신호 분석을 통한 화자 인식 및 자동 컷팅, 그리고 자동 프레이밍 같은 요소기술이 필요.
AI 다국어 자막 서비스
AI 다국어 자막 기술은 콘텐츠의 글로벌 유통을 위한 필수 요소로, 한국어 자막뿐만 아니라 다양한 외국어 자막 생성을 가능하게 함.
이 기술은 음성을 인식하여 한국어 자막을 생성한 후, 이를 다국어로 변환하는 과정으로 진행 이를 위해 DeepL 등 최신 AI 기술을 활용하여 한국어 자막을 영어를 비롯한 여러 외국어로 변환. 이때, 방송용어에 특화된 단어집을 구축하고 AI 모델을 학습시켜 변환 기능을 개선하면 방송 콘텐츠에 최적화된 자막 생성이 가능해질 것.
현재 영상, 미디어 산업에 AI도입의 초장기라 편집 및 자막에 많은 부분이 집중되어 있으나 최종적으로 시나리오 작업 -> 스토리보드작성 -> 영상생성 -> 편집 -> 방송송출까지 대부분을 AI가 대신하게 될 것.
AI가 만든 세계관에서 버츄얼 휴먼이 연기하는 드라마나 영화를 보게 될 것임.
디지털 휴먼 및 영상제작에 가장 필요한 것은 GPU이고 근미래에 AI가 영상을 제작하기 위해서는 고성능 GPU로 구성되어 있는 AI데이터 센터가 필수적으로 필요하게 됨. 얼마전 오픈AI에서 SORA를 대중에게 공개한 그날 서버가 다운 되었음. 서버 다운으로 미루어 보아 현재 5분짜리 영상을 만드는 서비스를 대중이 이용하는데 서버가 부족함을 알 수 있음. 향후에 1시간, 2시간 분량의 드라마,영화 제작을 위해서는 더 많은 데이터 센터가 필요 할 수밖에 없음.
광고, SNS 및 유통 서비스
인간의 수많은 행동 데이터를 바탕으로 제품 타겟층에 효율적인 광고를 노출 시키는 것이 광고의 키포인트. AI를 도입하게 되면 더 이상 고객이 온라인에서 무엇을 생각하고 행동하는지 질문할 필요가 없어지고 AI가 대신 해독하여 효율적인 광고를 제안할 수 있게됨.
또한 판매자가 SNS또는 소셜커머스에서 상품을 소개하기 위한 사전 작업(상품촬영, 상품소개, 편집)과 판매후 사후관리(클레임, AS, 반품, 교환) AI를 활용 하여 생산성을 높임.
- Meta 사례
샌드박스
마케팅 캠페인에 필요한 다양한 콘텐츠를 자동으로 생성해주는 도구. 여러 가지 버전의 문구를 자동으로 생성해줄 뿐만 아니라, 텍스트만 입력해도 배경 이미지를 자동으로 제작. 또한 세로형 콘텐츠인 릴스나 스토리 등에 최적화되도록 마케팅 소재를 자동으로 재가공 가능.

어드밴티지+ 오디언스
AI를 활용하여 타깃팅을 더욱 정교하게 수행함으로써 더 많은 전환을 이끌어 내며, 고객의 행동 패턴, 관심사, 구매 기록 등을 분석하여 개인별 맞춤형 광고를 제공하고, 광고 효과를 극대화.
메타는 소셜미디어 광고 및 SNS에 AI를 적극 도입. 종전에 광고주가 수동으로 처리해야 했던 타기팅과 예산 배분 등을 AI가 알아서 하게 되면서 광고주의 편의성을 높이고 광고 효율성을 극대화 하여 24년 메타의 연간 순이익률은 38%로 2023년 29%에서 10%포인트 가까이 늘어남. 이는 구글 29%, 아마존 9% 등의 순이익률을 넘어 서는 수치.(메타 측은 "메타의 광고주 대부분이 메타의 AI 기반 광고 도구를 사용하고 있다. 메타의 AI 광고 도구를 최소 1개 이상 사용하는 광고주가 6개월 전에는 100만명이었는데, 현재는 400만명에 달한다"고 밝혔다.)
- 쇼피파이 사례(Shopify Magic)
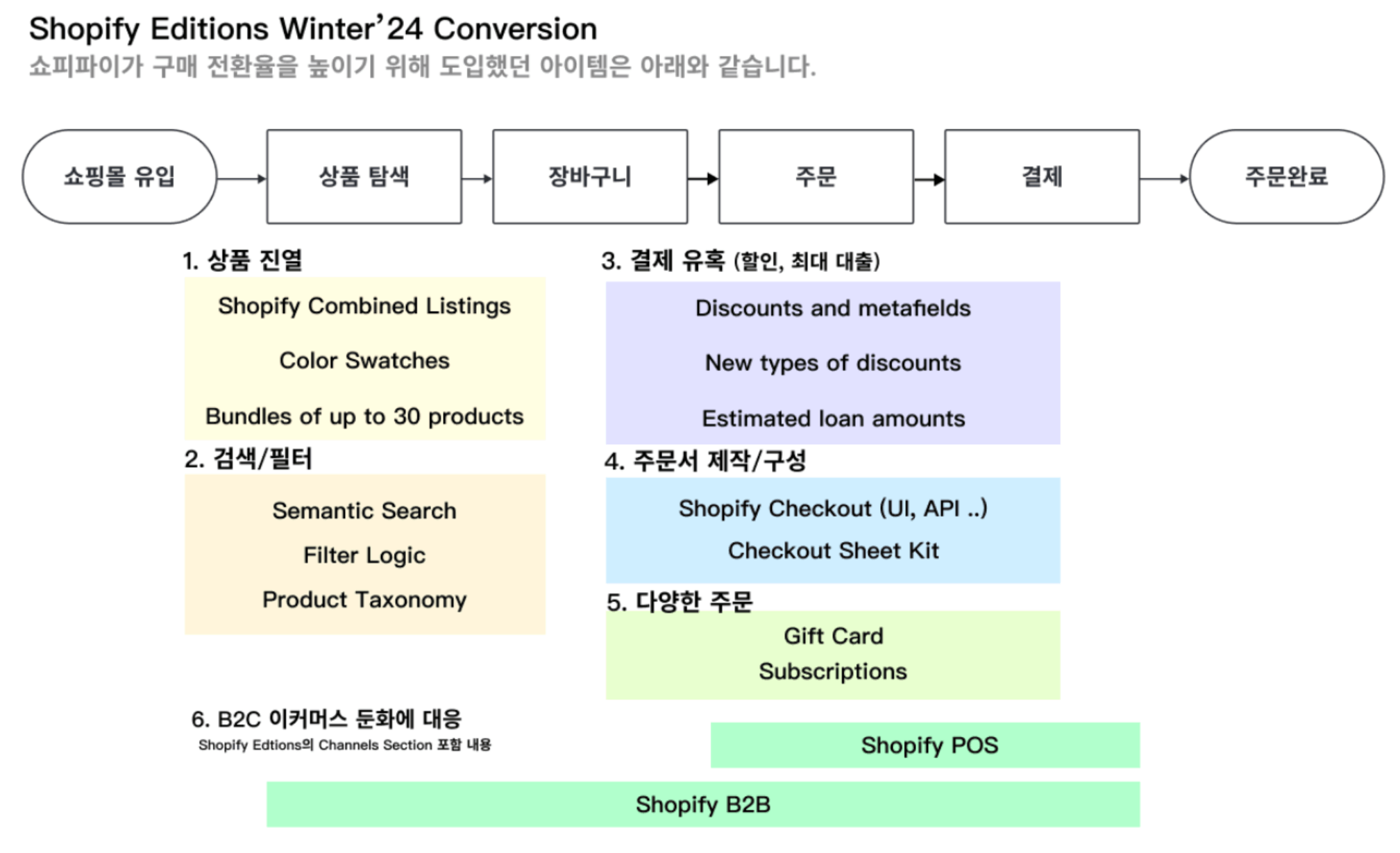
쇼피파이3d스캐너를 이용하여 3d 제품의 이미지를 생성하고, 어시스던트 서비스를 이용 쇼핑몰 사이트 내에서 구매 고객의 쇼밍을 지원하는 서비스 제공.
AI비서인 사이드킥은 채팅으로 모든 것을 설정을 해결할 수 있게함 예를 들어 '이용기간이 2024년 2월인 학생전용 10% 쿠폰을 생성해줘'라고 입력하면 바로 할인 쿠폰을 생성하고 판매량이 높은 제품 매출감소원인 등 판매량 증대를 위한 아이디어를 제공. 또한 제품의 이미지 배경을 바꾸거나, 제품설명을 만들거나 이메일을 보내고 본문 제목등을 추천 받음.
100가지가 넘는 기능으로 판매자 중심의 AI 사용환경 개선. 판매자가 상품을 노출시키고 판매 사후관리 까지 AI챗봇을 활용 손쉽게 처리할 수 있게 되면서 판매자 입점수 급증. 24년 4분기 매출이 26%증가하며 yoy두배에 이르는 7억 1,800만 달러의 순이익 달성
- 세일즈 포스 사례
온라인 주문부터 결제, 재고 차감·배송, 반품·환불 프로세스까지 ‘모든 단계’가 긴밀히 연동된 시스템에서 자동으로 처리. 고객 정보가 한 곳에 모여, 영업/물류/고객지원/마케팅팀이 모두 실시간으로 같은 데이터를 보며 업무를 진행.
대고객 알림(이메일, 문자, 앱푸시)과 업무흐름(워크플로우)이 자동화되어, 회사 입장에서는 인건비나 오작업을 줄이고, 고객에게 신속하고 정확한 서비스 제공.
이처럼, 주문→배송→반품→재고 관리가 단계별로 Salesforce와 연동되어 처리되면, 회사 내부에서는 협업이 수월해지고, 고객 입장에서는 ‘내 상품이 어디까지 왔는지, 반품은 어떻게 진행 중인지’를 즉각적으로 확인이 가능.
고객이 온라인에서 상품을 주문시 고객의 정보가 회사 서버에 자동으로 저장되어 고객 정보, 주문정보 등이 자동으로 분류 됨 -> 연동된 재고관리 시스템에서 자동으로 재고 파악 주문 전달 -> 물류팀이 발송 대기 주문 목록 확인 및 포장 -> 송장 스캔 -> 자동 재고 차감 및 고객 배송 문자 발송 -> 배송 완료 후 문자 발송 -> 고객 교환 및 반품 신청 -> 자동으로 택배사 호출 -> 반품 택배 수령 스캔 -> 재고 수정 자동완료 -> 고객 문자 발송 및 환불 자동처리
시장전망
실제 AI가 가장 많이 쓰고 실생활에 가깝게 효과를 느낄 수 있는 산업은 이커머스 시장 일 것으로 추측됨. 맥킨지에 따르면 이커머스 매출은 지난 5년가 두 배 증가했으며, 2026년까지 다시 두배 성장할 것으로 예상.
처음 온라인 사업에 진출 하게 되었을 때 느끼게 되는 가장큰 고민은 상품을 고객에게 어떻게 진열해야 할까, 상품에 대한 충분한 정보를 제공할 수 있을까? 고객이 원하는 사품을 어떻게 잘 찾게 할까?인데 이런 상황에서 AI가 프로세스, 수요예측, 마케팅, 유통과정 등을 자동화하게 되면 오프라인에서 활동하던 소상공인들의 온라인 입점이 가속화 되고 결과적으로 시장 규모가 더욱 빠르게 확대 될 것.
온라의 단점인 '고객의 체험의 부재'를 최근에는 유튜브 및 sns 컨텐츠에서 상품을 간접소개하고 sns내에서 관련 상품을 바로 비교하여 노출시켜 판매를 유도 함으로 극복하고 있음. 이러한 경험을 확장하여 고객의 생활하는 환경에서 필요한 정보를 빠르게 노출시켜(ai알고리즘 추천) 소비를 촉진해 거래 활성화 기대하는 전략이 지속적으로 발전 할 것으로 기대.
금융서비스
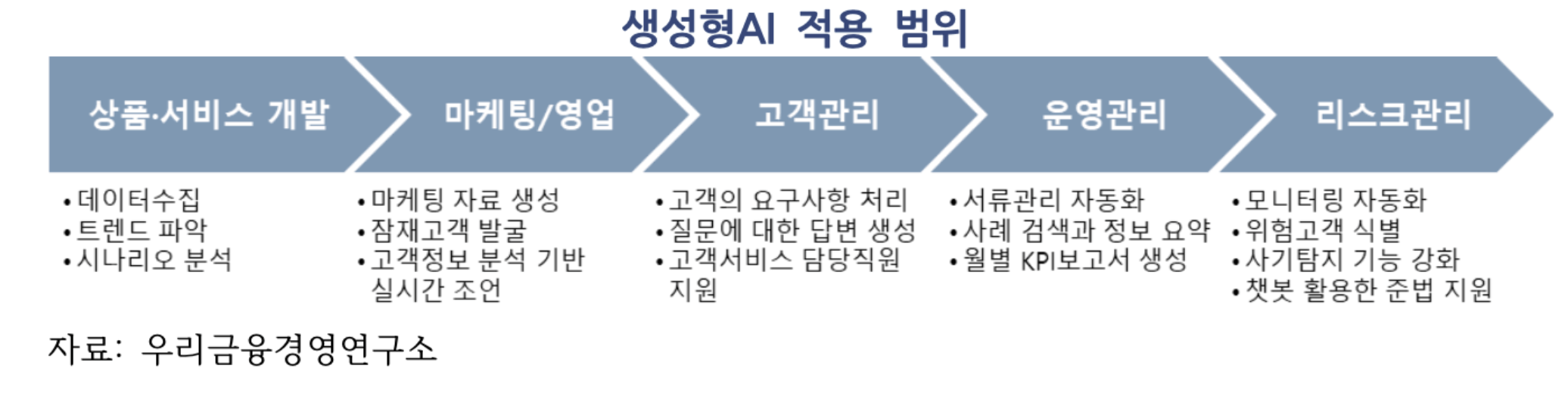
상품·서비스 개발
광범위한 데이터 수집을 통해 고객니즈의 트렌드를 파악하여 신상품을 개발하거나, 가격 결정을 위한 시나리오 및 모델링 분석
마케팅 및 영업
RM의 대고객 마케팅 자료 초안을 생성하거나, 데이터 분석을 통해 잠재고객을 발굴하고, 대화형 챗봇으로 대고객 영업 역량 강화.
- 기업 활동 모니터링을 통해 고객의 과제를 파악하고 관련 서비스를 선제안하거나, 고객와의 대화 내용을 분석하여 실시간 조언을 생성.
고객관리
대화형 챗봇으로 고객의 요구사항을 처리하는 등 고객과의 직접적인 커뮤니케이션을 강화하거나, 고객서비스 담당 직원이 활용할 수있도록 고객의 질문 내용, 주요 이슈 등을 요약 정리
- 시장, 투자, 정책 등에 대한 요약이나 고객 질문에 대한 답변을 생성하여 제공
운영관리
인사관리, 준법, IR, 재무관리 등 다양한 부서에서 서류관리 자동화, 사례 검색과 정보 요약 등의 기능을 개발할 수 있고 코드개발,잠재적 버그 식별, 데이터 관리 등 기술 분야에도 활용.
- 채용 시 직무기술서를 작성하거나 지원자의 이력서를 토대로 면접용 개별 질문사항을 생성
- 준법 부서에서 과거 사례를 검색하고 요약할 수 있는 Q&A 기능, IR 부서의 대내외 커뮤니케이션을 위한 초안 작성, 월별 KPI달성 보고서 자동 생성 등.
리스크관리
모니터링을 통해 위험 고객을 식별하거나, 사기탐지·리스크관리 관련 서류작업의 자동화, 규정 준수를 위한 대직원 챗봇 등이 가능
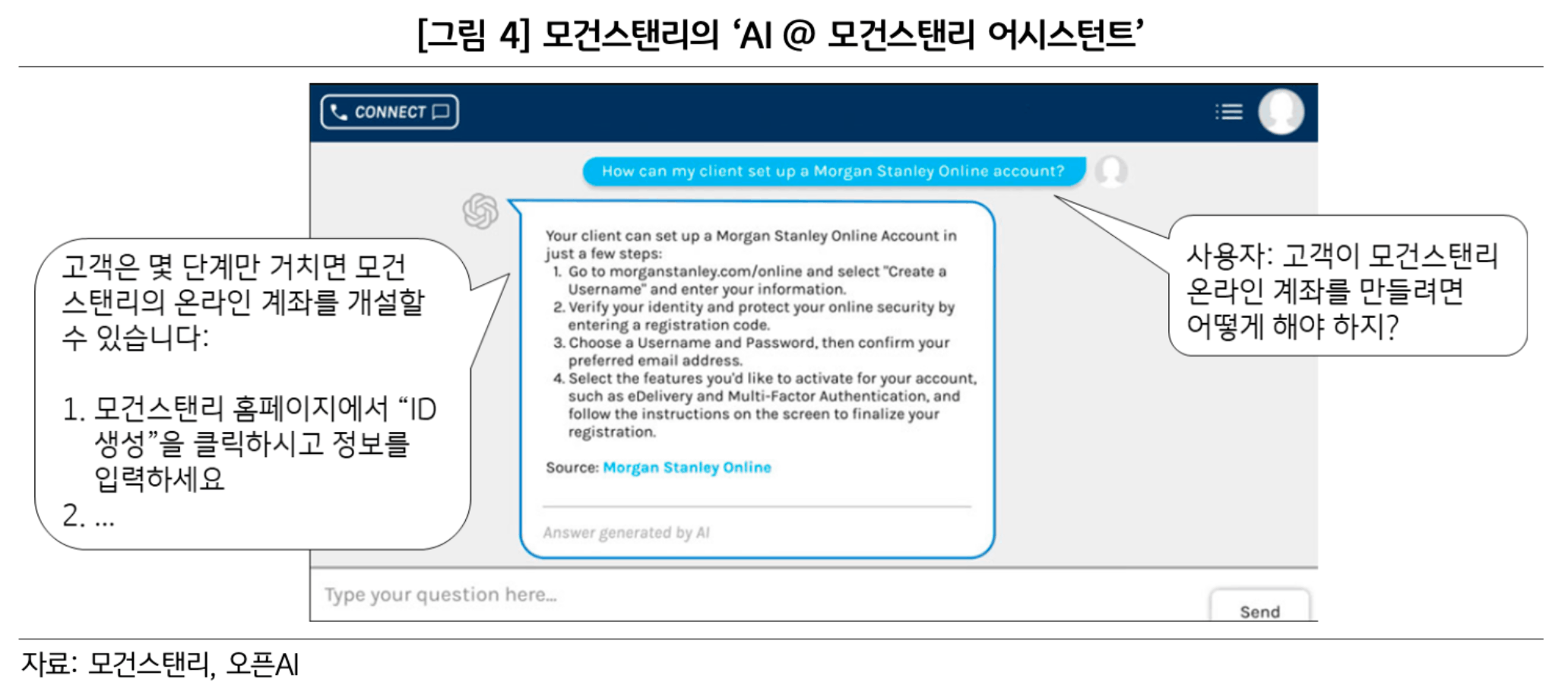
- Morgan Stanley 사례
ChatGPT제조사인 OpenAI와의 전략적 제휴를 통해 부유층 고객을 대상으로 자산관리 자문 서비스를 제공하는 RM이 활용할 수 있는 생성형 챗봇 ‘AI @ Morgan Stanley Assistant’를 출시(23.9월)
챗봇은 10만개의 보고서와 자료로 구성된 은행의 지적자본 데이터베이스에 접속하여 시장, 내부프로세스, 추천 등과 관련한 질의응답(예를 들어 연준의 금리인상 전망은 어떻습니까?, 고객의 IRA를 어떻게 개설합니까?,고객이 결혼을 준비하는데 어떤 도움을 줄 수 있을까요?)을 통해 직원이 고객에게 더욱 효과적이고 차별화된 조언과 서비스를 제공할 수 있도록 지원.
그외 고객과의 회의 내용을 자동으로 요약하고 후속 이메일을 생성하는 Debrief라는 도구를 테스트 중임.
- Mizuho 사례
일본 IT기업 Fujitsu의 생성형AI 플랫폼 기술로 Mizuho의 시스템 개발 및 유지관리 업무를 간소화하기 위한 생성형AI 테스트를 시작(23.6월)
시스템 설계 계획과 감사 프로세스에서 오류와 누락을 자동으로 감지하는 것을 테스트하여 품질개선 방법을 모색하는 것이 테스트의 목표
- 웰스파고 사례
미국 4대 은행인 웰스파고는 기존의 챗봇 ‘파고(Fargo)’에 생성형 AI를 적용하여 인간 직원이 수행하던 송금 등 다양한 업무에 도입하는 등 타 은행보다 선제적으로 생성형 AI 챗봇을 도입.
최고정보책임자(CIO) 친탄 메타(Chintan Mehta)는 자사의 생성형 AI 챗봇 ‘파고’가 연간 1억건 이상의 고객 응대 업무를 처리할 것으로 기대. 2024년 1월 IT 전문지 《벤처비트(VentureBeat)》와의 인터뷰에서 더 많은 기능을 추가하여 인간 직원의 역할을 대신하도록 발전시킬 계획이라 밝힘.
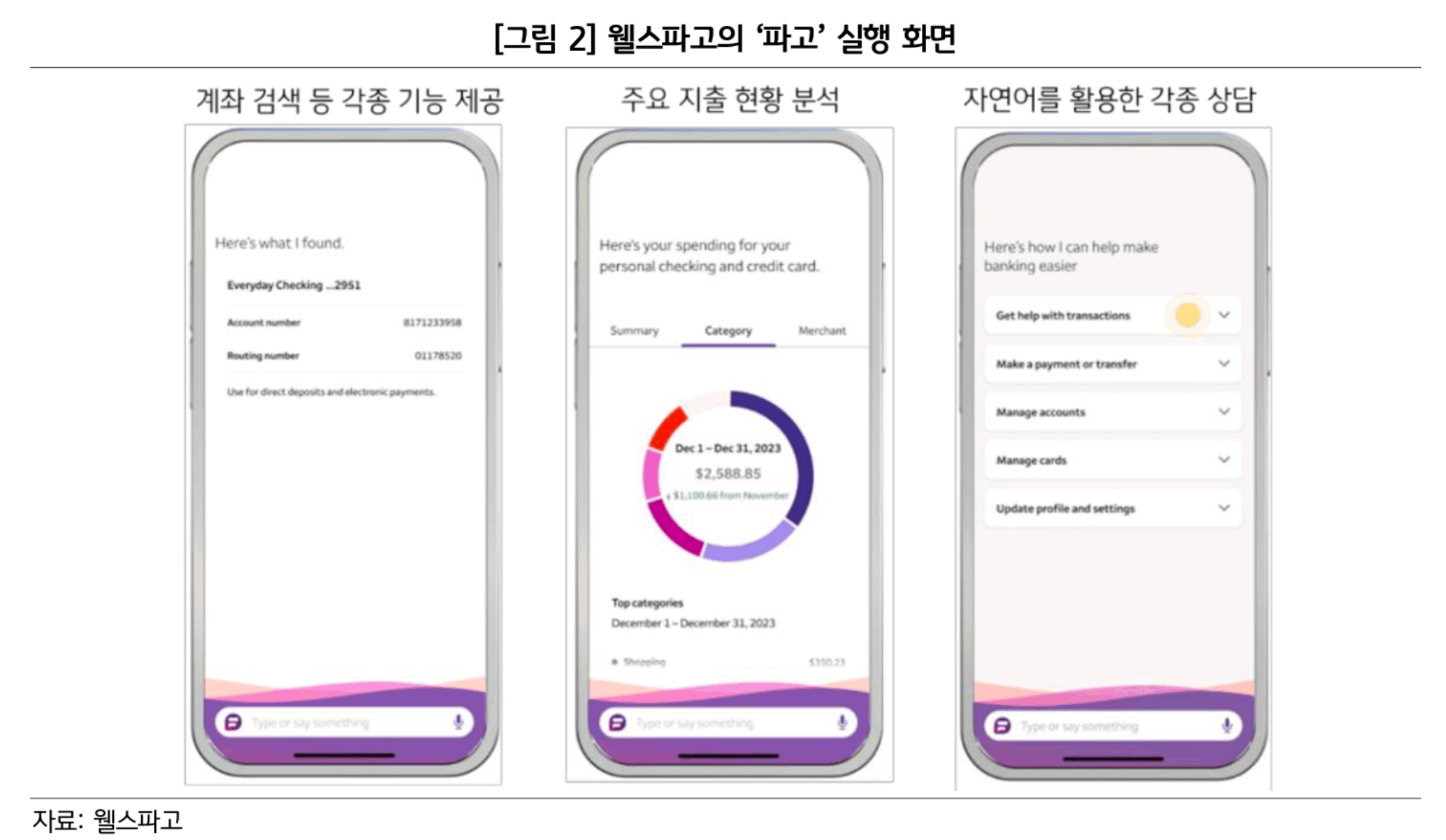
생성형 AI 챗봇 ‘파고’는 금융 상담과 자금 이체( 아직 파고의 이체 기능은 사용자가 자연어로 이체를 요청하면 직접 처리하는 것이아니라 이체 관련 서비스로 이동하는 형태), 각종 요금 납부 기능은 물론 고객의 금융 상황을 모니터링하여 금융 생활 개선을 위한 인사이트도 제공
특정 구매 건에 대해 대금이 중복 청구되거나 자동 이체 중인 구독 서비스 금액이 예고 없이 변경되는 등의 비정상적 결제 내역에 대한 알림을 제공
과거 거래 내역 분석을 통해 당월 계좌 잔고를 예측하고 자금 부족이 예상될 경우 알림을 제공
예산을 축소하고 저축 목표를 달성할 수 있는 지출 범위를 제안하며, 현금흐름을 요약 제 공하고 저축 목표 수립 및 달성 상황을 알려주는 등의 기능도 추가할 예정

향후전망
Mckinsey는 생성형AI가 은행업의 연간 수익의 2.8~4.7%의 비중에 해당하는 2천억 달러~3.4천억
달러의 생산성이 향상될 것으로 기대.
금융 소프트웨어 플랫폼 기업 Finastra의 조사에 의하면, 글로벌 금융회사들은 생성형AI를 맞춤화되고 개인화된 서비스에 대한 높아진 고객 니즈를 충족할 수 있는 핵심 수단으로 인식 중
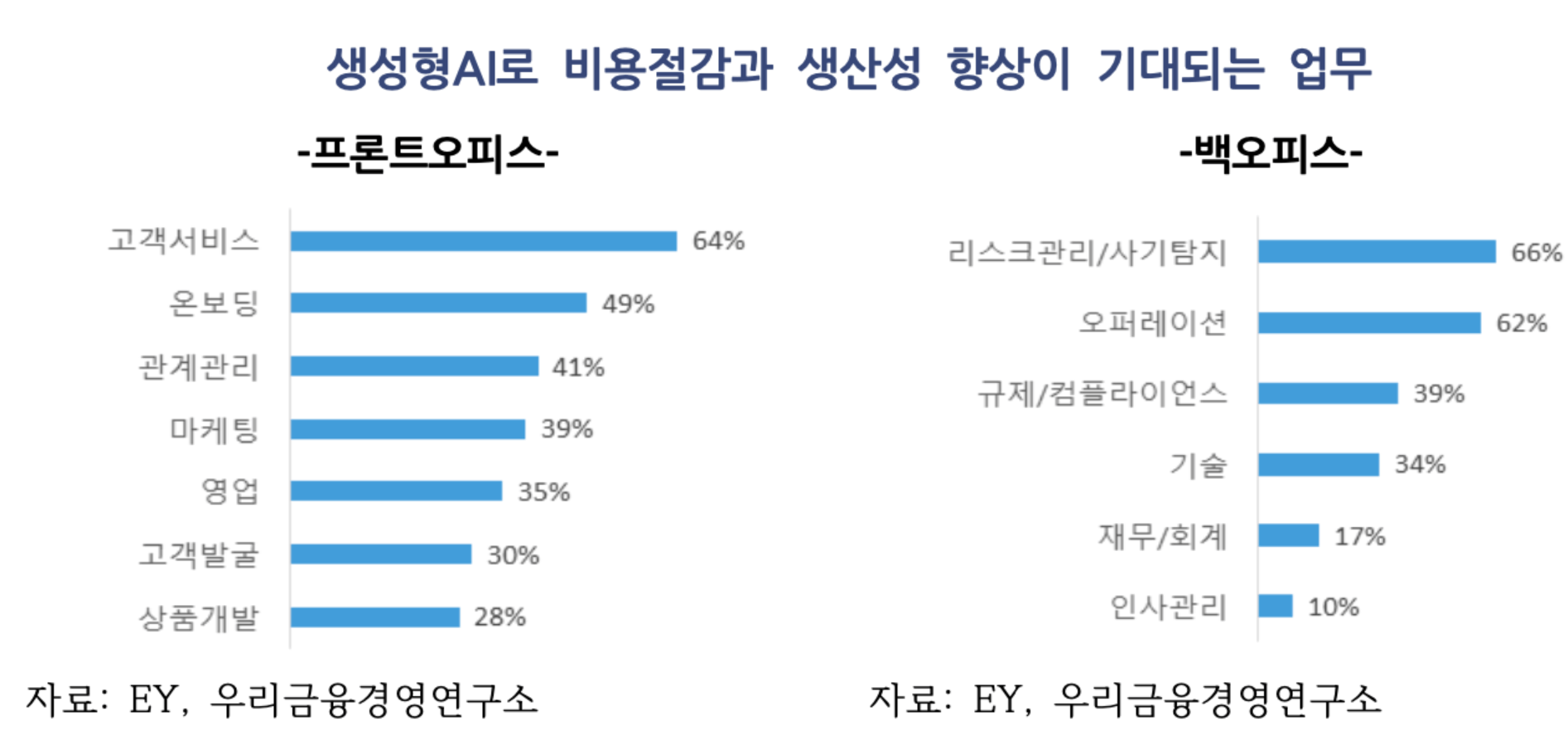
* EY가 글로벌 151개 은행을 대상으로 조사한 결과에 의하면, 프론트 오피스에서는 고객서비스(64%), 백오피스에서는 리스크관리(66%)가 생성형AI 적용으로 가장 큰 비용절감과 생산성 개선이 기대
* 예수금 규모 5천억 달러 이상인 대형은행은 상품개발을 최다(44%) 선택하는 등 은행 규모에 따라 차이는 존재
금융서비스는 은행, 보험, 증권사등이 동일하게 AI도입에서 첫번째로 추진하고 있는 것이 AI 챗봇으로 고객센터 상담원을 대신하여 고객을 응대 하게 하는 것임. 현재는 홈페이지 및 스마트폰 앱에서 챗봇을 통해 대고객 서비스를 제공하고 있으나 향후에는 콜센터 상담원 또한 AI로 대체될 가능성이 높음.
은행에서는 각종 심사관련하여 AI를 이용한 대출한도 계산 및 가부 여부를 전산에서 시스템화 하고 있으며, 향후에는 담보물건의 등기권리 조사와 같은 서류 검토 업무를 대신하여 직원의 생산성 향상에 기여할 전망.
보험사는 손해사정사들의 가벼운 보험금 지급업무를 AI가 대신하기 위해 시스템을 개발하고 있으며, 향후 손해사정사 들은 복잡한 손해배상 업무에만 집중 할 것으로 전망.
증권사는 고객에게 알맞은 상품 및 주식 포트폴리오를 제공하고 기업 분석 리포트 작성 기술적분석을 통한 매수, 매도 타이밍 예측 등 타 금융기관 보다 적극적으로 AI를 도입하여 향후 애널리스트, 펀드매니저를 대신한 AI가 운용하는 펀드 및 ETF가 나올 것으로 전망.
결론
AI 산업을 알아보는 긴 여정이 끝이 났습니다. 최초에 이 작업을 하게 된 계기는 "데이터 센터 확장이 계속 필요한가?","GPU가 계속 필요할 것인가? "에서 시작 되었습니다.
결론을 먼저 말씀드리면 GPU는 모르겠으나 데이터 센터는 "네 필요할 것 같습니다. 그것도 아주 많이요"
현재 우리가 검색서비스를 대신하고 일부 추론에 사용중인 chatGPT의 경우 방대한 AI기술의 일부분일 뿐입니다. 본인이 접하는 범주를 기준으로 생각하게 되는 '일반화의 오류'에 빠져 있다보니 더 이상 발전이 없는 것 처럼 보이고 이것을 어디에 더 사용할 것 인지 크게 쓸모 없이 보이기도 하고 불편한 점도 있는 것 처럼 느껴지기도 합니다.
하지만 정말 많은 산업군에서 불편하고 반복적인 작업을 AI가 대신하게 될 것이고, 인간이 수행하게 되면 수년이 걸리는 작업을 수십 배 빠르게 해내기도 하면서 아주 빠르게 넓은 영역으로 뻗어 나가게 될 것 입니다.
이미 제약회사의 신약개발 후보물질의 배합, 미디어 산업의 편집과 촬영, 금융회사의 대출 심사업무 등 퇴근시간을 늦추는 반복적인 작업을 AI가 대신하기 위해 많은 기업에서 자사에 특화된 애플리케이션을 개발하여 AI 에이전트를 활용하고 있습니다.
예를 들어 앞서 설명드린 세일즈포스나 쇼피파이의 서비스를 보면 판매자가 그 동안 일일이 수작업을 했던 사진편집, 상품설명, 제품의 배치등을 쳇봇과 대화를 통하여 자동으로 생성하고 있으며, 고객이 제품을 구매하여 발생하는 클레임, 반품, 교환 등 일련의 과정 또한 쳇봇이 대신하여 관리를 해주고 있습니다. 이런 서비스를 제공하는 쇼피파이의 24년 4분기 실적는 입점 판매자수의 폭증으로 동년대비 26% 증가 하였습니다. 앞으로 AI를 적극 활용하는 기업과 그렇지 못한 기업 간의 생산성과 매출 차이는 더욱 벌어질 것이며, 결국 AI를 도입하지 않는 기업은 점점 더 불리한 위치에 놓일 가능성이 크다고 할 수 있습니다.
이커머스뿐만 아니라, 모든 산업에서 AI 도입 여부가 기업의 생존을 결정짓는 시대가 될 것입니다. AI를 활용하는 기업과 그렇지 않은 기업 간의 생산성과 비용 절감 효과는 엄청난 차이를 만들 것이고, 결국 대다수 기업이 AI를 도입할 수밖에 없을 것입니다. 하지만 아직은 한국의 이커머스 시장만 보더라도 AI 기반 자동화 서비스를 제대로 제공하는 기업은 거의 없습니다. 즉, 대부분 기업들의 AI 도입은 이제 시작 단계에 불과 하다고 볼수 있습니다.
그렇다면 앞으로 얼마나 많은 데이터 센터가 필요할까요? 전 세계 기업들이 AI를 도입하고 물류, 생산, 업무 자동화를 진행한다고 가정하면, 수요는 지속적으로 증가할 수밖에 없습니다. 빅테크에서 데이터 센터를 지속 확장하고 있는 것도 이러한 맥락에서 이해할 수 있습니다. AI의 활용이 급격히 늘어나고 있으며, AI를 안정적으로 운영하기 위해서는 더 많은 서버가 필요하기 때문입니다.
물론 데이터 센터 확장이 영원히 지속되지는 않을 것입니다. AI 모델이 점점 최적화되면서 하드웨어에 대한 의존도가 줄어 일부 하드웨어 비용이 절감될 가능성도 있습니다. 또한 성장 속도가 전기자동차 캐즘현상 처럼 둔화될 수도 있습니다. 그러나 전기자동차를 타지 않고 내연기관 자동차를 탄다고 해서 인간의 삶에 큰 차이를 보이지 않지만, 인간과 비교하여 휴식이 필요 없는 AI에이전트는 기업의 생산성을 획기적으로 향상기킬 수 있습니다.
그리고 사용자가 폭발적으로 증가하고 AI의 활용 범위가 넓어지는 한, 트래픽 증가를 감당하기 위해 데이터 센터 증설은 필수적일 것입니다. 현재 AI의 주요 활용 사례는 시작에 불과하며, 휴머노이드 로봇과 자율주행 기술이 상용화 될때까지는 데이터 센터 수요가 지속적으로 증가할 가능성이 크다 하겠습니다.
참고문헌
250110 미래에셋증권 P95 25년은 생성AI 결실의 시작
삼정KPMG_CES2025_20250110
삼정KPMG-2025년-국내-주요-산업-전망-20241212
250109 미래에셋증권 P25 인터넷 서비스-제미나이와 빅테크의 파이
241216 미래에셋증권 P85 IT 서비스-글로벌 TMT 산업에서의 AI 주도 변화와 투자 기회
230201 Generative AI, 인공지능의 한계를 넘다 삼성증권
Statista(2023.7),‘Insights Compass 2023 - Unleashing Artificial Intelligences true potential’
Anthropic is expanding to Europe and raising more money, TechCrunch, 2024.5.13.

Disclaimer
- 당사의 모든 콘텐츠는 저작권법의 보호를 받은바, 무단 전재, 복사, 배포 등을 금합니다.
- 콘텐츠에 수록된 내용은 개인적인 견해로서, 당사 및 크리에이터는 그 정확성이나 완전성을 보장할 수 없습니다. 따라서 어떠한 경우에도 본 콘텐츠는 고객의 투자 결과에 대한 법적 책임소재에 대한 증빙 자료로 사용될 수 없습니다.
- 모든 콘텐츠는 외부의 부당한 압력이나 간섭없이 크리에이터의 의견이 반영되었음을 밝힙니다.
