낙민동추노의 팜
SK AI Summit 주요 Keynote 발표 내용 및 LLM 정리본 (By.메리츠증권, 김동관)

낙민동추노
2025.11.03
SK하이닉스의 주가를 보면서 FOMO가 오는것은 사실이지만, 그것보다도 더 근본적인 변화가 이루어지는 것 같아서 두고두고 보기위해서 Ctrl C, Ctrl V하였는데, 하고 나서 보니 가성비 떨어지는 정리인것 같고, 밤이여서 머리가 무거워서 그런지, 두번을 읽어봐도 뒤죽박죽임. 나중에 어떤 일들이 현실에서, 투자에서 일어날지 모르니 기록해두고 자주 자주 볼 예정
이런 Sea Change의 시대에 FOMO를 떠나서 투자를 할수 있다는 것, 그리고 육아휴직 기간이라는 것이 정말 다행이고, 운이 좋은 것 같다고 느껴진다

주제: AI Now & Next
Speaker: 최태원 SK그룹 회장
#Demand
AI 인프라 지출의 고성장 지속: 2020년 $230bn → 2025년 $600bn(연평균 +24%)
메가 프로젝트 가시화: OpenAI Stargate ~$500bn, Meta 2028년까지 $600–800bn 투자 계획 언급.
신규 플레이어(Neo cloud, 주권형 DC 등) 진입으로 빅테크 외 CAPEX 분산.
결론: 선형(Linear) 24% 성장이 아니라 구조적·기하급수(Exponential) 확대 가능성이 커짐.
#AI 수요 폭증의 4대 동력
(1) Inference 본격화
학습(Training) 중심 → 추론(Inference) 중심 수요 전환 Chain-of-thought / self-evaluation / self-consistency 등 “더 깊게 생각”하는 기법 확산 → 반복 추론 단계·토큰 사용량 증가 → Compute 수요 기하급수적 증가.
반례/완충 요인: 모델 아키텍처·양자화·KV cache 최적화 등으로 FLOPs·토큰 효율 개선도 병행. 정리: 효율화에도 불구하고 Inference 시대 진입 = 총량 기준 Compute 수요 순증이라는 데 업계 컨센서스
(2) B2B 도입의 가속
기업의 AI 도입 비중·예산 급증. IDC에 따르면 전세계 기업들의 Gen AI 솔루션 투자 규모는 2025년 $70bn → 2028E $200bn (+43% CAGR)
Anthropic 사례 언급: B2B 매출 비중 80%, 유료 기업 고객 30만+.
정리: B2B는 비용 대비 효익(경쟁력)을 이유로 채택 강제력↑ → 지출 민감도↓ → 수요 탄성 약화.
(3) Agentic AI의 상시화
24/7 상시 동작, 에이전트 간 상호작용, 실세계(가정/사무/공장)로 확장 → 지속적 추론·도구 호출·상태 저장 요구 → 지속형 Compute/Memory/Storage 수요 확대.
(4) Sovereign AI(국가 주도)
국가 단위 AI 인프라(주권형 모델/데이터/센터) 투자 본격화
기업 외에 ‘국가’가 새로운 수요 주체로 참여 → 총수요 상방 압력.
Inference 전환, B2B 강제 도입, Agentic 상시화, Sovereign AI가 동시에 겹치며 수요 곡선의 기울기 자체를 키우는 구조.
#공급·병목 구조(What breaks first?)
GPU(가속기) 공급 제약이 1차 병목이었고 현재도 진행형.
메모리 대역폭(HBM) 병목: 연산 대비 메모리 IO가 부족 → HBM 스택 수 급증(1→12개 이상), 메모리 소진 속도↑ → 공급 자체가 시스템 병목으로 부상.
전력/그리드/냉각: 대용량 전력 접속·송전 용량·열 밀도 관리가 차기 병목.
리드타임·정책·지정학: 팹/패키징/데이터센터의 착공→가동 긴 리드타임 + 입지/규제/수출통제 리스크.
수요 예측 불확실성: 중복 계산(Double/Triple counting), “익스포넨셜” 가정의 분산이 커 CAPEX 최적화 난이도↑.
#SK하이닉스의 대응책
(1) Capacity(생산능력)
최근 청주 HBM 신규 팹 완공(내년 본격 생산)
용인 클러스터(’27~): 대형 fab 4개 들어가며 대형 fab 하나 당 청주같은 fab 6개가 들어갈 수 있음
(2) Technology (기술)
초고용량 DRAM/HBM, HBF(Flash 기반 고대역폭 Persistent) 등으로 병목을 해결할 것
AI 데이터센터 레벨 솔루션: 칩레벨부터 시스템, 전력 ,운영을 포함해 가장 효율적인 인프라 솔루션 제공할 것
가산: 지난 8월, 국내 최대 B200 클러스터(Blackwell) 구축
울산: ~1GW급 AI 데이터센터(우선 AWS 100MW 계약, ’27 오픈 목표).
OpenAI와 서남권 합작 DC(차세대 아키텍처 상정) 공동 구축 예정
(3) “AI로 AI 문제 풀기”
메모리칩 생산과 DC 운영에 AI를 적용할 예정. AI를 통해 메모리칩 생산 효율과 속도를 올리고, DC 운영 자동화 및 가상화에 AI를 적용할 계획
엔비디아와 협업을 통해 메모리 생산 내 AI 적용을 본격 시작(Omniverse)
SK는 NVIDIA와 Digital Twin 솔루션을 도입해 SK하이닉스에 특화된 가상 공장을 만드는 중
Keynote Speech I: AI 혁신의 중심, SKT AI Infra의 Now & Next
Speaker: SK텔레콤 CEO 정재헌 사장
지금 우리는 AI 대전환이라는 역사의 한 가운데 서있음. SKT는 미래이자 핵심 동력인 AI 인프라 사업의 성격과 전략 방향에 대해 공유할 것
#AI 인프라 - 성과(NOW)
2025년 한 해에도 AI 분야에는 엄청난 변화가 있었음. 연초 DeepSeek 등 새로운 모델이 발표되고, 최근 동영상 생성 모델이 등장하는 등 예측하기 어려운 변화임. AI Agent 역시 단순한 챗봇을 넘어서 스스로 생각하는 실행 주체로 진화해 사용성을 넓히는 중.
이런 변화는 폭발적인 AI 인프라 수요를 창출. 글로벌 빅테크들의 천문학적 인프라 경쟁이 이어지는 중.
AI 3대강국을 목표로 하는 대한민국도 AI 고속도로 구축을 선언함. 과감한 예산 투입으로 AI 인프라 혁신을 추진 중.
SKT의 AI 인프라 전략은 국가 경쟁력의 핵심 축과 맞닿아있음.
SKT는 AI DC 구축을 선도함과 동시에 GPU 클라우드를 통해 AI 서비스의 접근성을 높이고 있음.
#울산 AI DC
지난 6월, AWS와 공동으로 약 7조원 투자해 울산 AI DC 건설하는 계약 체결. 국내 최대 규모의 AI DC 유치. 이는 SK 그룹의 전력, 시공 및 메모리 기술 등 핵심 역량을 결집하여 이뤄낸 성과
#Soverign AI
최신 GPU B200 1천장 규모로 국내 최대 GPU 클러스터 해인 구축. 해인은 독자 AI 파운데이션 모델에 활용하고 있음
SK텔레콤의 컨소시엄은 정부가 추진하는 독자 AI 파운데이션 모델 사업에서 주관 개발팀으로 선정
업무용 AI인 에이닷 비즈는 연내에 약 8만 명에게 AI 업무 파트너로 활용하게 될 것입니다.
#AI 인프라 - 향후 전략
AI DC 건설과 GPU 클라우드 구축으로 AI 인프라의 기반을 다져왔음. 이런 역량을 바탕으로 AI 인프라의 본격적인 확장을 추진
울산 AI DC를 확장하고, 서남권 AI DC를 신설해 국내 기반을 다진 후 글로벌 시장으로 진출할 것
통신사의 강점을 살려, edge AI 영역까지 인프라를 확장할 것
주요 글로벌 기업들이 우리의 AI DC 개발 역량에 주목하는 중. 울산 DC를 1GW 규모의 크기로 확대 구축하는 역사를 이어갈 것
글로벌 자본과 기술을 유치해 AI 인프라 허브로 가도록 노력할 것.
지난 10월 open AI와 국내 서남권 AI DC 설립을 위한 전략적 파트너십을 구축함. 이는 정부와 지자체, 글로벌 기업이 함꼐 추진하는 다자간 협력 첫 사례. Open AI와는 전용 DC 구축을 시작으로 기술, 정책, 산업을 함께 하는 협력 체계를 만들어가도록 할 것. 이를 통해 SKT는 전국을 잇는 대규모 AI 인프라 기반을 갖추게 됨.
AI 인프라의 확장은 국내에만 국한되지 않음. SKT는 그룹의 글로벌 사업과 연계해 글로벌 시장 진출 준비. SK이노베이션과 함께 베트남에서 에너지와 IT의 복합단지 전략에 기반한 AI 데이터센터 건설을 추진 중. LNG 발전소의 냉열을 활용하는 친환경 고효율 솔루션을 적용해 볼 예정. 이 밖에도 말레이시아나 싱가포르 등 글로벌 진출을 본격적으로 추진하는 중
#Edge AI
AI 서비스가 늘면서 통신사의 네트워크 인프라가 재조명을 받고 있음. SK텔레콤은 전국망을 활용하는 Edge AI 개념을 새롭게 제시.
이는 하이퍼스케일러의 데이터센터나 온디바이스 AI만으로는 대응하기 어려운 초저지연 저비용 수요 분야를 타겟으로 하고 있어 통신사만이 가능한 고유 영역
SK텔레콤은 빅테크들과의 협력을 강화하여 기술 생태계 조성에 앞장설 계획. 이미 동사는 Amazon과 중장기 협력 기반을 구축.
SK텔레콤의 인프라 기술력과 Amazon의 전문성을 결합하여 Edge AI 기술 확보에 역량을 집중할 계획
또한 NVIDIA 및 관계 연구 기관 등과 연합을 통해서 6G의 핵심 기술인 AI-RAN 공동연구를 추진하고 있음. AI-RAN은 제조 AI 확산의 핵심적인 인프라가 될 것
#Application의 확장
- 제조 AI의 확장
SK그룹은 반도체, 에너지 등 분야에서 대한민국을 대표하는 제조 역량과 기반 시설을 보유. 여기에 SK텔레콤의 AI 기술과 인프라를 결합하여 SK하이닉스 등 제조사의 제조 혁신과 생산성 향상을 추진할 계획
그 첫 단계로 제조 AI 전용의 Digital Twin 솔루션과 로봇 파운데이션 모델 개발을 진행. NVIDIA와 함께 RTX PRO GPU 2000대를 기반으로 제조 AI에 특화된 클라우드를 구축할 계획. 이는 제조의 혁신을 위해 기업 내부의 자체 클라우드를 구축한 아시아 최초의 사례. 이 클라우드는 SK하이닉스 등 제조회사의 AI 전환에 활용할 예정
SK텔레콤은 범용의 AI 인프라인 해인과 제조의 인프라를 모두 공급하는 아시아 유일의 사업자로 자리매김할 것
#AI DC 솔루션 확장
AI 수요의 폭증은 데이터센터 운영에 필요한 전력 확보의 문제, 그리고 천문학적으로 드는 구축 비용의 문제를 낳았음. AI 인프라 사업의 핵심 경쟁력은 비용의 효율성과 구축의 신속성에 달려 있음
SK텔레콤은 이에 대응할 수 있는 AI DC 솔루션을 제공할 계획
In-rack과 에너지 솔루션 등은 그룹 멤버사와 협력하여 구현을 하고 있고 Out-rack이나 서브클러스팅 솔루션 등은 저희가 직접 개발하면서 내재화를 추진 중
솔루션 경쟁력을 신속하게 확보하기 위해서 글로벌 선도 기업들과 긴밀히 협력하고 있음. Out-rack의 경우 슬라이드와 클러스터링의 경우 Penguin Solutions과 또 하드웨어와 관련된 부분은 Supermicro 등과 공동으로 개발을 하고 있음.
주제: AI 시대, SK하이닉스가 그리는 새로운 비전과 기술
발표자: SK하이닉스 곽노정 대표이사(CEO)
#현재 AI 환경
- AI 환경은 아주 빠르게 변화하는 중. 많은 AI 모델들이 개발되고 출시되며 AI 보급이 가속화. 이에 따라서 급격히 늘어난 데이터 이동을 지원하기 위해 하드웨어 기술 또한 빠르게 발전해야 함
- 하지만 안타깝게도 메모리 성능의 발전 속도가 프로세서 발전 속도를 따라잡지 못하고 있음(Memory Wall)
- Memory Wall을 해결하기 위해 많은 노력들이 이루어지고 있으며 메모리의 중요성은 더욱 강조되는 중. 메모리는 과거 단순한 컴포넌트에서 지금은 Key value product로 그 위상이 더욱 높아지고 있음
- 메모리에 요구되는 성능도 크게 높아져서 기존과 같은 방법으로는 달성하기가 어려워짐
#SKH의 Net-AI 시대 지향점 - Full Stack AI Memory Creator
- 지금까지 당사는 고객이 원하는 좋은 제품을 최적의 시점에 공급하는 것에 집중. 그 결과 Full Stack AI Memory Provider로서 입지를 다짐
- 지금 AI 시대에는 메모리의 중요성이 더 커져 Provider 역할만으로는 더 이상 충분하지 않을 것.
- 이에 오늘 이 자리에서 Provider를 넘어 더 높은 수준의 역할을 담은 Full Stack AI Memory Creator를 향후 SK하이닉스의 새로운 지향점으로 제시
- Full Stack AI Memory Creator란 고객이 가진 문제를 함께 고민하고 해결하며 더 나아가서 Ecosystem과의 활발한 interaction을 통해 고객이 원하는 것 이상을 제공하겠다는 의미.
- 이를 위해 SK하이닉스는 Partner 그리고 Eco-Contributor로써 Full Stack AI Memory를 Creation 하고자 함
- 지금까지의 메모리 솔루션이 컴퓨팅 중심으로 통합되었다면 미래의 뉴 메모리 솔루션은 메모리의 역할을 더욱 다변화하고 확장하여 고객들이 컴퓨팅 자원을 훨씬 효율적으로 사용할 수 있게 하고, AI 추론 병목을 구조적으로 해결할 수 있게 할 것

#Custom HBM
- 기존의 AI 시장이 범용성에 집중되었다면 최근에 그 수요는 특화된 효율성, TCO, Total Cost of Ownership의 최적화로 점차 확대되는 중
- HBM 또한 스탠다드에서 커스텀으로 제품 라인업을 확장하고 있음
- Custom HBM에서는 고객의 요청을 반영해 기존 GPU에 있던 일부 기능을 HBM Base Die로 옮겨오게 됨
- 이를 통해 GPU와 ASIC의 연산 성능을 극대화하고 GPU와 HBM 간 통신에 필요한 전력을 줄여서 TCO 효율성을 더욱 높일 수 있음

#AI-D
- 그동안 DRAM은 범용성과 호환성을 중심으로 발전. 이제는 DRAM의 영역을 더 세분화하여 각 영역의 요구에 가장 적합한 메모리 솔루션을 준비 중
(1) Optimization 관점: TCO 절감과 운영 효율화를 지원하는 저전력 고성능의 신규격 DRAM들을 준비 중
(2) Breakthrough 관점: Memory wall을 뛰어넘는 초고용량 메모리 및 자유자재로 메모리 할당이 가능한 솔루션을 개발 중
(3) Expansion 관점: 특정 응용만을 위한 DRAM이 아닌 응용의 한계를 넘어 로보틱스, 모빌리티, 산업 자동화 등과 같은 여러 분야로 Usage를 확장한 고품질 DRAM을 준비 중

#AI-N
AI-N P(Performance): 고성능을 강조한 AI-N입니다. 작은 청크 사이즈를 통해 기존보다 대폭 향상된 입출력 속도를 지원하는 초고성능 SSD
AI-N B(Bandwidth): AI-N-B는 HBM 용량 증가의 한계를 보완할 수 있는 방안으로 NAND를 HBM과 같이 활용할 수 있도록 제품을 개발 중
AI-N D(Density): 초고용량 SSD로서 NAND의 강점으로 하여 HDD와 경쟁하기 위한 가격 경쟁력 강화 제품

#SK하이닉스 메모리 로드맵

#AI 시대의 경쟁 방식
AI 시대의 경쟁은 혼자만의 역량이 아닌 고객과 파트너들과의 협업을 통해 더 큰 시너지를 만들어내고 더 나은 제품을 만들어 나가는 업체가 결국 성공.
저희는 이러한 고객 만족과 협업의 원칙하에 최고의 파트너들과 기술 발전 협업을 더욱 강화해 나갈 것.
현재 당사는 주요 글로벌 파트너들과 AI 및 차세대 반도체 기술 분야에서 다양한 형태의 협력과 논의를 지속하고 있음.

#AI 협력 사례
- NVIDIA: HBM 및 AI 제조 혁신 관련 기술 협력과 Omniverse Digital Twin 기반의 공동 활용 방안을 논의
- OpenAI: 고성능 메모리 적용을 위한 장기적 관점의 파트너십 가능성을 모색 중
- TSMC: 차세대 HBM 관련 기술 협력
- Schneider Electric: 차세대 NAND 기술인 HBF의 국제표준화 관련 공동 논의
- Naver Cloud: 데이터센터 효율화를 위한 차세대 메모리 소프트웨어 최적화 협력 등을 진행 중
주제: 메모리 중심 컴퓨팅의 실체와 미래 : Memory 병목 해소의 중요성
발표자: David A. Patterson (Google, UC Berkeley)
1. 서론: 메모리 지향 도메인 특화 아키텍처 (Memory Oriented Domain Specific Architecture) 컨셉
발표자는 점심 이후 세션으로 기술적인 디테일을 많이 다룰 것이고, 레이싱카 비유를 쓴다고 말한다. 레이싱카는 한 가지 목적을 위해 극단적으로 최적화된 차라는 점에서, “한 가지 목적을 아주 잘하는 시스템을 설계한다”는 주제와 연결된다. 이게 바로 Memory Oriented Domain Specific Architecture라는 테마다.
2. 21세기에 일어난 두 번의 거대한 변화(Sea Change)
2.1 첫 번째 변화: Dennard Scaling의 종료와 Multicore
2000년 무렵 인텔 최신 마이크로프로세서는 전력 소모가 약 35W 수준이었고, 성능은 18개월마다 2배 가까이 증가하고 있었다. 그래서 당시에는 사람들이 기존 하드웨어가 멀쩡해도, 친구 것이 더 빠르면 자기 것도 그냥 바꿔버릴 정도였다. 이런 식의 성능 향상이 가능했던 핵심은 Moore’s Law와 Dennard Scaling이었다.
Dennard Scaling의 아이디어: 트랜지스터의 임계전압(threshold voltage)을 낮추면, 칩 안에 더 많은 트랜지스터를 넣고 더 빠르게 동작시켜도 전체 전력은 크게 늘어나지 않는다. 즉, 트랜지스터 수와 속도는 계속 올라가는데 전력은 여전히 수십 W 수준으로 억제 가능했다. 개발자(프로그래머) 입장에서는 “강력한 단일 프로세서” 하나만 있으면 됐다.
그런데 Dennard Scaling은 2006년쯤 사실상 끝났다. 더 이상 전압을 낮추고 주파수를 올려도 전력 한계를 넘지 않을 수 없게 됐다. 프로그래머들은 계속 “큰 단일 코어 하나”를 원했지만, 그렇게 만들면 이제는 전력이 너무 많이 나와서 불가능해졌다.
그래서 일반 목적 컴퓨터(general purpose computers) 업계가 취한 유일한 선택지가 있었다: “거대한 단일 코어” 대신 “작고 효율적인 코어 여러 개”를 넣는 것. 그게 바로 Multicore다. 이렇게 하면 이진 호환성(Binary Compatibility), 즉 같은 명령어 집합을 유지할 수 있으면서 성능을 더 낼 수 있다. 하지만 성능을 끌어내려면 병렬 프로그래밍(Parallel Programming)을 직접 해야 했다.
중요한 점: 업계가 Multicore로 간 건 병렬 프로그래밍을 너무 잘 해결해서가 아니라, 다른 방법이 없었기 때문이었다. “절박함 때문에 간 것”이 첫 번째 큰 지각 변동이었다.
요약하면: Dennard Scaling의 끝 → 전력 벽 → 단일 초고성능 코어 불가능 → Multicore로 전환.
2.2 두 번째 변화: Moore’s Law 둔화와 Domain Specific Architecture
두 번째 변화는 Moore’s Law의 둔화다. Moore’s Law가 느려지면서 범용 CPU(general purpose CPU)의 성능 향상을 예전처럼 밀어올리기 어려워졌다. 2000년대 초에는 GPU가 그래픽 전용 가속기라는 작은 틈새(niche) 시장에 있었다. 그 외 대부분은 범용 CPU가 담당했다.
그런데 Moore’s Law가 느려지자, 매 세대마다 60%씩 뛰던 성능 향상이 이제는 10% 수준으로 떨어졌다. 하지만 프로그래머들은 여전히 “엄청난 성능 점프”에 중독돼 있었다. 그래서 할 수 있는 선택지가 바뀐다.
하드웨어 설계자들이 택한 해법은 Domain Specific Architecture였다. 즉 “모든 걸 잘하는 범용 프로세서” 대신 “한 가지 작업만 아주 잘하는 전용 아키텍처”를 만든다. 이런 전용 아키텍처는 어떤 특정 도메인에서는 훨씬 빠르지만, 모든 작업을 다할 수는 없다. 발표자는 이 개념을 Hennessy와 함께 투링상(Turing Award)을 받을 때 쓴 논문에서도 강조했다고 언급한다.
문제는 도메인을 어디로 잡느냐였다. 그래픽(GPU)은 2000년대 초 기준으로 시장이 작았고, 더 큰 시장이 필요했다. 마침 AI가 2015년 즈음부터 급부상하면서 “AI”라는 방대한 도메인이 등장했고, 모두가 가속을 원하게 됐다. 이게 Domain Specific Architecture의 핵심 타겟이 된다.
요약하면: Moore’s Law 둔화 → 범용 CPU 성능 증가 정체 → 대신 AI 같은 특정 영역에 특화된 Domain Specific Architecture(예: GPU, TPU 등)로 전환.
3. 왜 AI에서는 하드웨어가 더 자유롭나 (소프트웨어 관점)
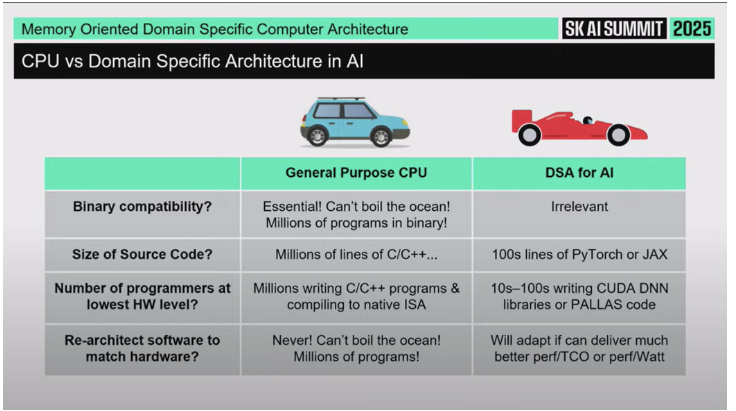
기존 전통적 컴퓨팅(가운데 있는 ‘전통적인 자동차’에 비유):
범용 CPU 생태계에서는 특정 ISA(Instruction Set Architecture)에 대한 Binary Compatibility가 절대적이었다.
소프트웨어는 수백만 줄짜리 코드베이스였고, 수백만 명이 그 코드를 유지·개발하고 있었다.
그래서 하드웨어 쪽에서 “기발한 아이디어”가 나와도, 소프트웨어가 바뀌어줄 가능성이 없었다. 즉 하드웨어가 소프트웨어를 뒤흔들 수 없었다.
반면 AI 도메인:
Binary Compatibility를 아무도 크게 신경 쓰지 않는다.
모델(예: PyTorch 코드)은 수백 줄 정도로 비교적 짧고, 지능(intelligence)의 원천은 “엄청난 양의 데이터로 학습시킨 파라미터”에 있다. 즉 지능은 코드 라인 수가 아니라 훈련 데이터에서 온다.
모델을 만드는 사람(최적화하는 사람) 수도 상대적으로 적다. 그래서 이 도메인에서는 소프트웨어 스택이 새로운 하드웨어에 맞게 재적응(retarget)할 준비가 돼 있다.
결과:
AI 쪽은 하드웨어 설계자가 훨씬 상상력을 자유롭게 펼칠 수 있는 시장이다.
게다가 AI 시장은 돈을 더 내고서라도 Domain Specific Memory 같은 특화된 자원을 사려는 의지가 강하다. 그래서 지금 이 방향(메모리 중심 도메인 특화 아키텍처)이 사업적으로도 성립 가능하다.
발표자는 현재 High-Bandwidth Memory(HBM)를 “training을 위한 오늘의 Domain Specific Architecture”라고 부르고, 곧 “inference를 위한 내일의 Domain Specific Memory”로 High-Bandwidth Flash(HBF)를 이야기하겠다고 예고한다.
4. 메모리 한계가 병목이 되는 이유
최근 AI에서 큰 발전으로 언급되는 Transformer 모델, Mixture of Experts 등은 공통적으로 메모리 시스템에 더 큰 압력을 준다. 그래서 Memory Oriented Architecture가 필요하다.
동시에 기존 메모리 기술의 진화 속도도 둔화 중이다. SRAM은 사실상 정체(plateau), DRAM은 과거보다 훨씬 느린 개선 속도, Flash는 아직 상대적으로 개선이 계속되긴 하지만 전반적으로 예전만큼 급격하지 않다.
다행히 AI 소프트웨어 스택은 유연해서, HBM이나 High-Bandwidth Flash 같은 새로운 메모리 인터페이스(완전히 새로운 소재가 아니라 “기존 메모리 기술에 새로운 인터페이스/구성”을 붙이는 방식)에도 적응할 수 있다는 점이 강조된다. 즉 완전히 새로운 미지의 메모리 물질을 안 써도 된다. HBM은 DRAM 진화와 함께 갈 수 있고, High-Bandwidth Flash(HBF)는 기존 Flash 공정의 발전을 그대로 따라간다.

5. High-Bandwidth Memory(HBM)와 High-Bandwidth Flash(HBF)
5.1 구조적 유사성
논리적으로 보면 HBM 스택(왼쪽, 노란색)과 HBF 스택은 매우 비슷하다.
둘 다 여러 개의 칩을 적층(stack)한다. DRAM 기반 스택(HBM) / Flash 기반 스택(HBF).
칩들은 Through Silicon Via(TSV)로 상호 연결돼 매우 높은 대역폭을 제공하고, 인터포저(interposer) 위에 배치된다. 즉 상호연결 구조와 집적 형태가 유사하다.
5.2 장점 (HBF vs HBM)
발표자가 제시한 비교 박스(하단 박스 기준):
HBF는 표준 DRAM 대비 용량(capacity)이 약 10배 크다.
표준 Flash 대비로 보면, 대역폭(bandwidth)이 10배, 용량(capacity)도 10배 수준이라고 설명한다.
반대로 말하면, “낮은 용량에서의 HBM 대비”로 보면 HBF는 100배 수준의 대역폭을 제공한다는 식의 비교도 언급된다. 즉 HBF는 대역폭과 용량에서 모두 매우 매력적이다.
5.3 단점 / 제약
하지만 Flash 특성은 여전히 Flash다:
쓰기 횟수(write endurance)가 제한적이다.
읽기 지연(read time)이 DRAM보다 길다.
접근 단위(block size)가 훨씬 크다.
쓰기(write) 속도가 느리다.
그래서 “맞는 타겟(workload)”을 찾으면 어마어마하게 좋지만, 만능은 아니다. 이건 전형적인 Domain Specific Architecture의 성격이다: 특정 용도엔 환상적이지만 모든 데에 쓸 수는 없다.

6. High-Bandwidth Flash(HBF)의 대표적 사용처 (Inference 중심)
발표자는 HBF가 어디에 쓰이면 좋은지 구체적으로 짚는다:
1.LLM Weights / Parameters
Large Language Model(LLM)에서 “Large”는 결국 weight(파라미터) 개수가 수십억 단위라는 뜻이다.
추론(inference) 단계에서는 이 weight가 거의 바뀌지 않는다. 즉 고정된, 거대한 읽기 전용(read-mostly) 데이터다.
이런 정적인 대규모 파라미터 저장에는 HBF가 이상적이다.
2. Mixture of Experts (MoE)
MoE는 연산량(compute)을 줄이는 대신 훨씬 더 큰 파라미터 풀(=공간, capacity)을 갖는 방식이라고 설명한다.
즉 연산을 덜 하고, 대신 더 많은 “전문가 expert” 가중치 세트를 갖고 거기서 일부만 활성화한다.
이 구조는 “공간은 매우 큼 / 실시간으로 전부 바뀌지는 않음”이라는 특성을 가지므로, 큰 용량과 높은 대역폭이 장점인 HBF와 궁합이 좋다.
3. RAG (Retrieval-Augmented Generation)
발표자는 RAG를 “프롬프트에 교과서를 같이 붙여주는 것 같은 느낌”이라고 설명한다.
즉 어떤 질문을 할 때, 관련 지식을 검색·가져와서 LLM에 같이 넣어 정확도를 높이는 방식이다.
RAG용 지식 베이스는 “말도 안 되게 거대하고(gigantic), 거의 바뀌지 않는(변경 빈도 낮은)” 데이터다. 이것도 HBF에 적합하다.
4. 사전 계산된(pre-computed) KV cache
흔히 쓰는 입력 패턴에 대해 Key/Value 캐시를 미리 계산해 둔 형태.
이것도 추론 시 빠른 접근이 중요하지만 빈번한 업데이트는 적은 데이터라서 HBF 후보가 된다.
발표자는 이것을 “조금 더 마이너하고(esoteric) 특수한 유즈케이스”라고 표현한다.
요약: HBF는 “거대하지만 거의 안 바뀌는 읽기 위주 데이터” → 즉 추론(inference) 측에 특히 잘 맞는다.

7. HBF/HBM이 들어갈 수 있는 제품 영역
발표자는 “작년에 출하된 다양한 클래스(class) 의 컴퓨터 수”를 보여주는 슬라이드를 언급하며, 어디에 쓸 수 있는지를 묻는다. 답은 사실상 전 범위다.
데이터센터(Data Center): 가장 명확한 타깃. LLM 추론용 파라미터/지식 저장 등에 사용.
개인용 컴퓨터(PC): 예를 들어 내 모든 이메일과 문서 전체를 이 로컬 장치에 넣어두고, 거기에 대해 질의(query)할 수 있게 한다고 상상해볼 수 있다.
스마트폰(Smartphone): 더 큰 용량을 스마트폰 쪽에서 쓸 수 있게 되면, 지금은 데이터센터급에서만 가능한 모델 품질/경험을 휴대폰에서 직접 돌릴 수 있는 방향으로 갈 수 있다.
즉 활용 범위가 데이터센터만이 아니라 개인 디바이스까지 내려올 수 있다는 얘기다.
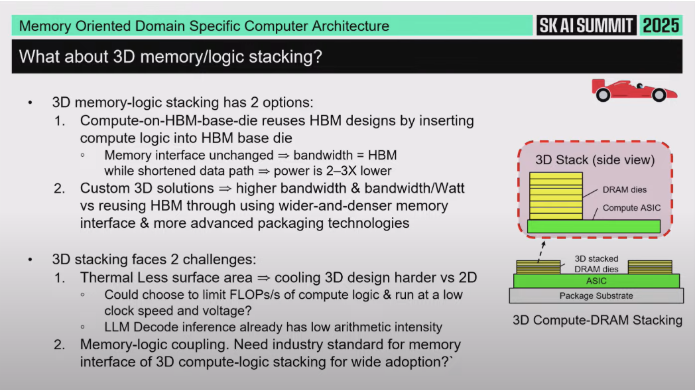
8. 3D 메모리-로직 적층(3D memory logic stacking)
발표자는 이제 “어떻게 이런 걸 실제로 만들 것인가”로 넘어가며 3차원 적층(3D stacking) 아이디어를 말한다. 이건 오전 세션에서도 언급됐다고 한다.
8.1 두 가지 버전
HBM Base Die에 연산 넣기
HBM은 맨 아래에 Base Die가 있다.
이 Base Die 자체에 compute(연산 기능)를 집어넣는 아이디어가 있다.
이렇게 하면 기존 HBM과 동일한 대역폭을 확보하면서, 메모리와 연산 사이 거리가 짧아져서 전력을 낮출 수 있다(전력 효율 이점).
이건 기존 HBM 구조를 자연스럽게 확장한, 비교적 “표준적”인 형태라고 설명한다.
2. Custom 3D solution (맞춤형 3D 솔루션)
HBM 스택이라는 틀에 얽매이지 않고, 훨씬 더 넓고 특화된 인터페이스/배선을 잡는 방식.
즉, 더 와이드하고 더 도메인 특화된 구조를 메모리-로직 간에 직접 설계한다.
둘 다 “메모리와 로직(연산)을 3D로 붙인다”는 공통 컨셉을 갖는다.
8.2 기술적 과제
냉각(Cooling): 메모리 스택이 로직(연산 블록) 위에 올라가는 형태면, 그 아래 칩이 몇 W를 태울 수 있는지가 한계가 된다. 쉽게 말해 열(thermal) 문제가 매우 빡세다.
어떤 연산을 거기에 둘 것인가: 너무 compute-heavy한 것(연산이 많은 블록)을 그 위에 두면 발열/전력 문제가 심해진다. 그래서 inference 과정 중에서도 상대적으로 연산량이 낮은 단계가 적합하다. 발표자는 Large Language Model의 inference 단계에서 “decode”라는 부분이 비교적 compute가 적다고 설명하면서, decode 쪽이 적층 대상 후보일 수 있다고 말한다.
표준화(Standardization): 이걸 실제 산업에서 쓰려면 한 회사 전용으로만 할 수는 없고, 업계 표준(standard)을 만들어야 할 가능성이 높다. 즉 여러 회사가 맞춰 쓸 수 있는 표준 형태가 필요하다.
9. Processor in Memory vs Processing Near Memory
발표자는 이제 더 “너드 같지만 중요한” 주제로 넘어간다: Processor in Memory (PIM) vs Processing Near Memory (PNM).
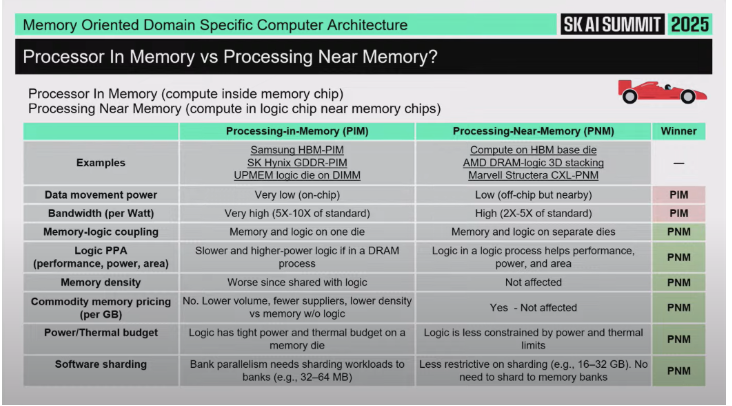
9.1 정의
Processor in Memory (PIM)
DRAM 칩 안에 프로세서를 넣는 것.
즉 메모리 뱅크 바로 옆(혹은 안쪽)에 연산 유닛을 박는다.
Processing Near Memory (PNM)
메모리 뭉치(memory stack 혹은 메모리 어레이) 옆에 별도 로직 칩을 두는 것.
물리적으로 매우 가깝지만, DRAM 공정 안에 로직을 억지로 넣는 건 아니다.
9.2 항목별 장단점 비교
① 데이터 이동(data movement) / 전력(power for moving data)
메모리 뱅크 바로 옆(칩 내부)에 프로세서가 있으면 데이터가 거의 안 움직여도 되므로 전력 소모가 훨씬 작다.
이 측면에서는 PIM이 압도적으로 유리하다 (“fantastic”). PIM 승.
② 대역폭(bandwidth)
칩 내부에 붙어 있으면 이론적으로 엄청난 대역폭이 나온다.
따라서 이 항목도 PIM이 더 좋다.
PNM도 좋긴 하지만, 칩 내부만큼은 아니다.
③ 전력/성능/면적 (power/performance/area 효율)
여기서 판세가 바뀐다.
DRAM 공정(메모리 공정)은 로직(프로세서) 구현에 최적화된 공정이 아니다. DRAM 공정 안에서 만든 프로세서는 면적 효율·성능 효율이 떨어지고, 전력 대비 성능이 나쁘다. 즉 PIM은 비효율/낭비가 생길 수 있다.
반면 PNM은 로직은 로직 공정(진짜 Logic chip)에, DRAM은 DRAM 공정에 각각 최적화해서 둘 수 있으므로 이런 문제가 적다. 그래서 이 관점에서는 PNM이 유리하다.
④ 메모리 밀도(memory density) / 코스트(cost)
PIM에서는 메모리 다이에 로직을 넣는 순간 메모리 면적 효율(밀도)이 떨어지고, 그 결과 더 이상 범용(commodity) DRAM이 아니다. 즉 비싸진다.
또한 같은 다이에 로직을 얹으면 전력 제한도 같이 걸린다. 메모리 동작을 망치지 않으려면 온도/전력 상한선이 낮아진다.
PNM은 메모리는 메모리대로, 프로세서는 프로세서대로 따로 가니까 이 제약이 덜하다.
⑤ 소프트웨어(software)
발표자는 “소프트웨어가 왕(software is king)”이라고 강조한다.
어떤 구조든 소프트웨어가 제대로 활용하지 못하면 아무 소용 없다.
핵심은 sharding이다.
9.3 Sharding의 의미와 제약
Sharding이란, 데이터를 여러 “버킷(bucket)”으로 쪼개서, 어떤 연산을 할 때 필요한 데이터 대부분이 그 버킷 안에 있도록 배치하는 걸 의미한다.
만약 PIM/PNM 구조에서 필요한 데이터의 절반만 그 근처에 있고 나머지는 멀리 있다면, 멀리 있는 데이터 때문에 결국 성능이 묶여버린다(병목).
따라서 “거의 모든 접근이, 그 근처(local)에 있는 버킷에서 끝난다”는 식으로 애플리케이션을 쪼갤 수 있어야 한다. 이걸 소프트웨어가 해줘야 한다.
9.4 Sharding 관점에서 본 PNM의 실용성
PNM은 “메모리 칩 스택 전체” 단위로 로직에 가깝게 둘 수 있다.
반면 PIM은 DRAM 내부의 “메모리 뱅크(bank)” 단위처럼 훨씬 더 잘게 쪼개진 단위다.
스택 전체 vs 단일 뱅크는 규모 차이가 거의 1000배 수준까지 난다고 표현한다.
즉 Sharding을 현실적으로 적용하기 훨씬 쉬운 쪽은 PNM이다.
그래서 전반적으로 보면, Processing Near Memory 쪽이 더 넓은 범위의 애플리케이션에서 통용 가능한 기술로 보인다고 말한다.
10. 모바일 디바이스 vs 데이터센터: 다른 제약
발표자는 “내가 구글에서 일하다 보니까 기본적으로 데이터센터를 떠올리지만, 모바일은 좀 다르다”고 전제하고 모바일 쪽 특수성을 짚는다.

LLM 크기 자체가 다름
휴대폰/모바일 디바이스에서 돌리는 Large Language Model은 데이터센터 모델보다 훨씬 작다.
즉 파라미터 수가 적다 → Sharding이 더 쉬워진다.
Batch size 차이
데이터센터에서는 여러 요청을 묶어서(batch) 처리한다.
휴대폰에서는 그런 식으로 여러 요청을 동시에 묶지 않는다. 사실상 batch size = 1이다.
batch size가 1이면 모델 메모리 풋프린트(동시에 잡아야 할 활성 상태)가 줄어든다. 모델이 더 작게 유지된다.
데이터 타입(정밀도) 차이
휴대폰은 더 좁은 정밀도(narrower data types)를 공격적으로 쓴다.
데이터센터보다 더 낮은 비트폭으로 수치 표현을 줄여 연산량과 메모리 요구량을 낮춘다.
이렇게 하면 Processor in Memory처럼 발열 제약이 큰 구조에서도, 모바일에서는 그나마 현실성이 올라간다.
결론적으로:
만약 AI 소프트웨어가 휴대폰용 애플리케이션을, “한 덩어리당 32GB가 아니라 32MB 정도 크기의 조각”으로 잘게 나눌 수 있다면,
그럼 휴대폰 내부에서도 고대역폭·저전력 Processor in Memory 스타일의 칩을 실제로 만들 수 있을지도 모른다. 즉 모바일은 PIM조차 현실화할 여지가 생긴다.
11. 마무리 (정리 및 Q&A 예고)

발표자는 마무리로 핵심 메시지를 다시 정리한다:
1.21세기에는 두 번의 해일급 변화(Sea Change)가 있었다.
Dennard Scaling의 종말로 전력이 가장 큰 문제가 되었고, 그 결과 업계는 Multicore로 전환했다.
약 10년 뒤 Moore’s Law의 둔화로, 성능 향상을 위해 Domain Specific Architecture로의 대전환이 일어났다. 이 전환은 현재 AI에서 가장 적극적으로 진행 중이다.
2. AI에는 막대한 투자가 이뤄지고 있고, 이 덕분에 두 가지 모두가 가능해졌다:
Domain Specific Processor (예: GPU, TPU)
Domain Specific Memory (예: High-Bandwidth Memory, High-Bandwidth Flash)
이건 범용 기술이 예전만큼 빨리 안 좋아지고 있기 때문에, 특화 설계가 더 빨리 성공할 수 있는 환경이라서 가능하다.
3. “소프트웨어는 왕(software is king)”이라는 점은 그대로이지만, AI Software Stack은 새로운 하드웨어에 맞춰 적응하려는 의지가 있고 실제로 적응이 가능하다. 그래서 혁신적인 메모리 지향 설계가 예전보다 성공 확률이 높다.
4. 로직-메모리 3D 적층(3D Stacking of logic and memory)은 매우 유망하지만, 열(thermal) 문제와 표준화(standardization)가 과제다. 또한 Processor in Memory와 Processing Near Memory 중에서, PNM은 더 폭넓은 영역에 적용 가능해 보인다. 다만, 휴대폰처럼 모델이 작고 batch size=1인 환경에서는 일부 PIM 형태도 실현 가능할 수 있다.
#Q&A
1. 서로 다른 프로세서(GPU / TPU / NPU 등)가 있으면 프로그래밍도 다 달라지는가?
질문 요지
GPU, TPU, NPU 등 서로 다른 종류의 프로세서들이 많아지고 있다. 그럼 각각이 전부 다른 프로그래밍 인터페이스(API, 개발 방식)를 요구하게 되는 건가? 고객(모델 개발자) 입장에서 보면, 프로그래밍이 하드웨어마다 달라지는 건지 궁금하다.
답변 정리
1.AI 쪽은 이미 사실상 표준 프레임워크 위에 올라가 있다.
현재 AI 애플리케이션은 PyTorch가 가장 널리 쓰이는 표준 프레임워크다.
그 외에도 JAX, TensorFlow 같은 프레임워크가 있다.
모델은 이런 비교적 고수준(high-level) 프레임워크 위에서 정의/작성된다. 즉 개발자들은 주로 이 레이어에서 일한다.
2. ‘학습(learning)’과 ‘지능(intelligence)’은 주로 데이터에서 온다.
모델의 가치는 방대한 학습 데이터와 그로부터 얻어진 파라미터(가중치)에서 나온다.
즉 고객(모델을 갖고 있는 회사) 입장에서는 “코드를 어떻게 작성하느냐”보다 “데이터로 학습된 모델”이 핵심 자산이다. 이건 하드웨어별로 크게 안 바뀐다.
3. 하드웨어별 커스터마이제이션은 ‘아래층(로우레벨)’에서 일어난다.
실제로는 프레임워크 → 런타임 → 커널/라이브러리 레벨에서, 하드웨어마다 최적화가 필요하다.
이건 해당 하드웨어를 만드는 회사들이 책임지고 짠다.
NVIDIA는 자사 GPU용으로 그 소프트웨어 스택(라이브러리, 커널 등)을 직접 만든다.
Google도 TPU에 대해 그걸 한다.
AI 가속기 스타트업들도 자기 하드웨어에 맞는 “고품질 소프트웨어 라이브러리”를 직접 만들어야 한다.
즉 고객은 계속 PyTorch 같은 표준 인터페이스를 쓴다고 느끼지만, 그 밑단에서 하드웨어 벤더가 자기 칩에 맞게 최적화 레이어를 깔아준다. 이게 스타트업에겐 큰 허들이다. “하드웨어만 잘 만들면 되는 게 아니라, 그걸 잘 돌리는 소프트웨어 스택까지 줄 수 있느냐?”가 진짜 경쟁력이다.
4. 그래서 고객 시점에서는 ‘아니요, 크게 다르게 안 느껴진다’.
고객은 프레임워크(Pytorch 등)로 모델을 짠다.
그 아래에서 하드웨어 벤더가 알아서 자기 칩에 맞게 매핑(mapping)한다.
그래서 “GPU냐 TPU냐 NPU냐에 따라, 고객이 완전히 다른 방식으로 프로그래밍해야 하느냐?”에 대한 답은 “아니다.”
단, 이게 가능하려면 벤더가 엄청 잘 만든 소프트웨어 라이브러리를 제공해야 하고, 이게 스타트업에게 항상 어렵다.
5. 컴파일러 층의 표준화 시도도 있다.
컴파일러 쪽에서는 중간 표현(intermediate language) 계층을 표준화하려는 시도가 있다.
예로 MLIR 같은 intermediate language가 언급된다.
업계 회사들이 “우리가 쓰는 컴파일러를 이 공통 intermediate로 맞출 수 있지 않을까?”라는 식으로 검토 중이다.
하지만 실제로 가장 어려운 건 여전히 “하드웨어별 라이브러리 품질” 문제다. 단순히 중간 언어 하나 맞춘다고 끝나는 게 아니다.
요약
겉(프레임워크)에서는 거의 표준화돼 있어서, 고객 입장에서는 GPU든 TPU든 NPU든 비슷하게 쓸 수 있게 가고 있다.
하지만 속(로우레벨)에서는 업체마다 미친 듯이 최적화된 소프트웨어 라이브러리를 직접 깔고 있고, 거기가 진짜 승부처라서 스타트업들에 특히 어렵다.
MLIR 같은 공통 중간 언어 시도도 있지만, 결국 핵심은 “그 하드웨어용으로 제대로 최적화된 라이브러리/소프트웨어 스택을 벤더가 줄 수 있느냐”다.
2. HBM+PNM(Base Die에 로직 넣는 방식)에서 누가 더 큰 가치를 가져가나? (DRAM 회사 vs 시스템 회사)
질문 요지 (해석 정리)
현재 HBM 스택을 보면 Base Die가 있고, 그 위치에 로직(logic), 즉 연산 기능을 더 붙이는 게 가능하다.
이건 Processor Near Memory(PNM) 아이디어와도 비슷하다: 메모리 가까이에 연산을 둬서 성능/대역폭을 끌어올리는 구조.
질문자는 “이런 구조에서 누가 더 ‘밸류(가치)’를 가져가나?”를 묻는다.
SoC/시스템 회사(즉 hyperscaler, 시스템 통합사?)가 주도해서 커스텀 Base Die를 만들고 이득을 가져가나,
아니면 DRAM 회사(HBM 만드는 회사들)가 스스로 연산을 붙여서 표준화된 ‘스마트 HBM’을 팔면서 더 많은 마진을 가져가나?
다시 말해: Processor Near Memory 시대에 주도권은 누구에게 가느냐?
답변 정리
기본 구조 재확인
지금 말하는 건 HBM의 Base Die에 추가 로직(= Processor Near Memory 성격)을 넣는 시나리오다.
이는 사실상 “Processing in/near Memory” 아이디어의 현실 버전으로 볼 수 있다.
2. 가능한 사업 모델은 크게 두 가지라고 본다.
모델 A: 특정 시스템 회사와 HBM 업체가 같이 커스텀 설계
예: 대형 시스템 회사(예: hyperscaler, GPU 회사 등)가 HBM 제조사와 직접 협력해서, 자기만 쓸 수 있는 커스텀 Base Die를 만든다.
이렇게 하면 그 HBM은 사실상 그 회사 전용이 된다.
이 경우 당연히 그 시스템 회사가 자기 워크로드에 최적화된 메모리+로직 스택을 확보한다. 경쟁 우위는 그 회사 쪽으로 간다.
패터
모델 B: HBM 회사 스스로 표준화된 “연산 들어간 HBM” 제품을 판다
DRAM/HBM 회사가 “이제 우리도 그냥 메모리만 파는 게 아니라, 연산 내장된 고부가가치 HBM을 스탠다드 SKU처럼 만들겠다”는 방식.
즉 누구나 사서 쓸 수 있는, 연산 기능 포함 HBM(또는 HBF) 같은 걸 제품화하는 모델이다.
이건 메모리 회사 입장에서 “우린 이제 단순 부품 말고 더 높은 마진의 솔루션을 판다”로 갈 수 있어서 매력적이다.
3. 그리고 현실적으로는 “둘 다 가능하다”고 본다. 즉 특정 고객 맞춤(Custom) 라인과, 누구나 살 수 있는 표준(Standardized) 라인이 공존할 수 있다.
4. 메모리 업체의 동기
발표자는 직접적으로 SK hynix를 대신해 말할 수는 없다고 전제하면서도, 메모리 회사들의 오랜 욕망을 언급한다.
메모리 회사들은 역사적으로 “프로세서 회사들만큼의 수익성(높은 수익성)을 갖고 싶어 했다.”
즉 DRAM은 원가경쟁/싸움이라 마진이 낮은데, 프로세서는 설계 지능과 IP 덕에 높은 마진을 가져간다.
그래서 메모리 회사 입장에서는 “우리가 단순히 비트만 파는 DRAM 벤더가 아니라, 연산까지 포함된 고부가 HBM/PNM 솔루션 업체가 되면 마진 구조가 프로세서 쪽에 가까워질 수 있다”는 강력한 유인이 있다.
이건 메모리 업체에게 매우 매력적인 게임 체인저다.
5. 시스템 회사 쪽 동기
반대로 hyperscaler나 GPU/ASIC 업체 같은 시스템 회사는 “남이 다 같이 쓸 수 있는 표준품”보다 “우리 워크로드 전용으로 최적화된 전용 Base Die”를 원할 가능성이 높다.
그게 경쟁력(성능/전력 효율/총소유비용 TCO)을 좌우하기 때문이다.
그래서 이들도 HBM 업체와 손잡고 커스텀 PNM형 Base Die를 설계하려는 유인이 충분하다.
6. 결론적으로 ‘누가 이득을 보냐?’에 대한 답
둘 다 이득 볼 수 있다.
시나리오 A에서는 특정 대형 시스템 회사가 독점적으로 최적화된 PNM형 HBM을 가져가서 자신들만의 차별화된 플랫폼을 갖는다.
시나리오 B에서는 HBM/DRAM 회사가 자체적으로 연산을 넣은 표준 제품을 팔아서, 지금보다 더 높은 수익성을 메모리 단에서 직접 챙긴다.
발표자는 특히 메모리 회사들이 “프로세서 회사처럼 높은 수익성”을 전통적으로 부러워했기 때문에, 이 시장(Processor Near Memory / Processor in Memory 형태의 HBM, HBF)은 메모리 회사들에게 굉장히 매력적인 업사이드라고 본다.
AI 인프라 병목의 해법 : 메모리 중심 아키텍처가 열어갈 미래
(1) 패널 소개
Philip Wong (TSMC 최고과학자 / 스탠퍼드 교수)가 좌장을 맡는다. 오늘 세션은 David Patterson이 방금 얘기한 “메모리 병목과 AI 인프라”를 더 깊게 들어가서, 앞으로 기술적으로 뭘 해야 하는지, 또 앞으로 어떤 게 더 중요해질지를 논의하겠다고 말한다.
패널은 Meta의 Changkyu Kim(메타에서 LLM 학습/최적화/서빙 인프라 책임), MemVerge의 Charles Fan(메모리 중심 소프트웨어 회사, SK hynix 파트너), 그리고 SK hynix의 김호식(차세대 AI용 메모리 시스템 R&D 총괄).
Changkyu Kim (Meta):
Meta에서 LLM 인프라(학습, 최적화, 서빙)를 전세계 규모로 설계하고 있다. Frontier는 시스템 co-design이다. 즉 하드웨어, 소프트웨어, 수치 표현 방식(numerics), 모델 구조까지 전부 같이 바꿔서 토큰 처리량(throughput)을 올리고, 레이턴시와 전력/비용을 줄이는 게 목적이다. 결국 “필요한 대역폭과 레이턴시를 꼭 필요한 위치에 정확히 준다”가 본질이다.
Charles Fan (MemVerge):
MemVerge는 메모리 중심(memory-centric) 소프트웨어 회사로, SK hynix와 협력하고 있다. 공유 메모리, 지속되는 에이전틱 메모리(persistent agentic memory) 같은 영역을 보고 있다. 본인은 17년 동안 스토리지 시스템을 만들었고, 지금은 메모리 중심 소프트웨어를 만들고 있다.
김호식 (SK hynix):
SK hynix에서 Memory System Research를 맡고 있고, AI 하드웨어/소프트웨어 최적화, 차세대 메모리 솔루션 개발을 책임지고 있다. “메모리는 원래도 중요했지만, Generative AI 이후로 시스템 전체가 메모리 중심(memory centric)으로 바뀌고 있다.”고 말한다.
(2) 메모리 병목이 실제로 의미하는 것
Wong이 묻는다: “Patterson이 말한 ‘메모리 병목’은 실제 현장에서 뭘 의미하나? 비용, 사용자 경험에 어떤 영향을 주나?”
Changkyu (Meta)가 답한다:
지금 업계의 무게중심은 “대규모 학습”에서 “대규모 추론”으로 이동 중이다.
추론에서는 토큰 생성 속도가 메모리 대역폭에서 막힌다. 토큰 생성은 계산(compute) 문제가 아니라 데이터 이동(data movement) 문제다.
우리는 모델에게 더 긴 컨텍스트를 기억하라고 요구하고 있다. multi-turn reasoning, tool 사용, 긴 context 등은 매 토큰마다 참조해야 할 활성 컨텍스트를 더 길게 만든다. 이 때문에 추론은 점점 메모리 바운드가 되고, 레이턴시가 늘어나고, 비용이 오른다.
“Inference의 경제성은 점점 ‘byte per token(토큰당 몇 바이트를 옮겨야 하나)’과 ‘bandwidth per watt(전력 대비 대역폭)’에 의해 좌우된다.”
한 줄로 말하면: 이제 사용자 경험에서 지연(latency)을 정하는 건 메모리다.
좌장이 정리한다: 긴 컨텍스트로 갈수록 쿼리 레이턴시가 길어진다. 사용자 경험이 그만큼 나빠진다. 이건 AI 서비스 상용화에 직접적인 제약이다. Changkyu도 동의한다: “맞다. 추론은 레이턴시 민감하고, 메모리가 그 레이턴시를 결정한다.”
(3) 소프트웨어 레이어에서의 대응 (MemVerge 관점)
Wong: “소프트웨어 레이어에서는 이 병목을 어떻게 다루나?”
Charles (MemVerge):
추론 시 병목은 크게 두 가지다.
메모리 용량: Transformer는 모델 파라미터 외에도, 입력 토큰들을 처리하면서 KV cache를 계속 만든다. context가 길어질수록 이 KV cache 메모리 사용량은 선형~초선형으로 커진다. 즉 모델이 단순히 ‘파라미터 크다’ 문제가 아니라 ‘context 길다 → KV cache 폭증’ 문제다.
분산 추론에서의 상태 공유: 한 번의 추론이 여러 GPU에 걸쳐서 수행되는데, 특히 요즘은 분산 inference(예: Dynamo 스타일)로 더 그럴 수밖에 없다. 이러면 KV cache 등 상태(state)를 GPU들 사이에서 고속으로 옮기고 공유해야 한다. 이건 새로운 fabric(예: memory fabric)과 그 위에서 동작하는 소프트웨어가 필요하다.
즉 하드웨어 혁신만으로 안 되고, 이 상태 공유/배치 문제를 다룰 소프트웨어도 같이 나와야 한다. MemVerge는 SK hynix와 이런 쪽을 같이 보고 있다고 말했다.
Wong이 “Patterson이 말한 persistent context 얘기 좀 더 해달라”고 하자, Charles는 AI의 ‘기억’을 3층으로 정의한다:
모델 Weights (=학습된 지식)
컨텍스트 기반 단기 작업 메모리(KV cache 등)
Persistent context (=에이전트의 장기 기억 / 사용자 히스토리 / 모델이 아직 내장하지 않은 지식)
이 세 번째 계층은 사실상 새 스토리지 계층이다. LLM이 새로운 컴퓨터라면, 이 persistent context는 새로운 저장장치(storage)다. 이건 장기적으로 High-Bandwidth Flash(HBF) 같은 고대역폭 비휘발성 계층이 맡을 가능성이 있다.
(4) 메모리 디바이스/아키텍처 관점에서 뭐가 부족한가?
Wong이 SK hynix의 김호식에게 묻는다: “메모리 디바이스 기술, 아키텍처, 소프트웨어 관점에서 지금 뭐가 부족해?”
김호식(SK hynix):
병목은 분명히 **용량(capacity)**도, **대역폭(bandwidth)**도 둘 다다. 어느 쪽이 더 중요하냐고 하면 상황마다 다르다. 그래서 “어느 한 요소만 올리면 끝”이 아니라, 용량/대역폭/지연(latency)/전력까지의 트레이드오프 밸런스를 찾아야 한다.
그 밸런스를 찾으려면 모델 → 소프트웨어 엔진(서빙 엔진, 예: vLLM 등) → SoC → 메모리까지 전 스택에서 협력(co-design)해야 한다. 단품으로는 답이 안 나온다.
기존 메모리 시스템은 계층형 피라미드(hierarchy)로 생각했지만, 앞으로 AI 시스템은 “병렬적으로 나뉜 여러 메모리 tier를 동시에 운용”하는 그림이 나올 거라고 본다. 예를 들어 어떤 데이터는 HBM, 어떤 데이터는 CXL 메모리, 어떤 데이터는 LPDDR 등, 단일 위계가 아니라 분산된 heterogeneous 구성이 될 수 있다. 소프트웨어는 이 KV cache, 모델 weights 등을 그에 맞게 ‘똑똑하게’ 배치해야 한다.
Wong도 동의한다. 과거엔 메모리 계층이 “속도/지연 vs 용량/밀도” 한 축이었다면, 지금은 지속성(persistency), 내구성(endurance), 에너지 효율 같은 새로운 축까지 같이 고려해야 한다고 한다.
(5) “그럼 실제로 게임 체인저가 뭐가 될 거 같나?” (HBM, HBF, CXL 등)
Wong: “AI 데이터센터를 겨냥할 때, 앞으로의 게임 체인저는 뭐라고 보나?”
김호식(SK hynix):
HBM은 이미 게임 체인저였고 앞으로도 계속 그럴 것이다(HBM5-6… 업계 농담으로는 ‘HBM97’까지 필요하다고 Jensen Huang이 말했다고 언급). 시장은 더 큰 용량, 더 높은 대역폭을 원한다.
동시에 에너지 소비(전력)도 병목이 되고 있다. 대규모 메모리를 유지·구동하는 전력 자체가 AI 시스템의 한계 중 하나다.
해결책 중 하나는 compute near memory, 즉 메모리 근처나 내부에 연산을 붙이는 것이다. 예: HBM의 Base Die(로직 다이)에 단순 컨트롤러 이상의 연산 기능을 집어넣거나, 메모리와 로직을 3D로 적층해서 데이터 이동 거리를 줄인다.
어떤 연산을 거기에 둘지는 신중해야 한다. 너무 특정 애플리케이션에만 쓰는 니치 연산을 넣으면 재사용성이 떨어진다. 그래서 범용적으로 많이 쓰이는 연산(예: matrix-vector multiplication 등)을 후보로 보고 여러 옵션을 탐색 중이다.
Wong이 “그럼 소프트웨어 레벨에선 뭘 바꿔야 하나?”라고 묻자 Charles(MemVerge)는 이렇게 답한다:
메모리는 크게 두 부류로 나뉘어갈 거다.
near compute memory: 연산장치와 매우 가깝게 붙어서 초고대역폭/초저지연을 제공하는 메모리 (HBM이 대표적). 여기에는 weights와 일부 KV cache 같은 “즉시 필요한 활성 상태”가 들어간다.
shared memory: 여러 컴퓨팅 노드가 공동으로 접근하는 메모리 풀. 여기서는 용량(capacity)과 공유가 더 중요해진다. 일부 KV cache와 persistent context가 여기에 들어간다.
shared memory 쪽은 기존 “스토리지”가 하던 영역과 겹치며, 앞으로는 스토리지와 메모리의 경계가 무너질 거다. 다만 여기선 지연(latency)을 마이크로초(µs) 단위 수준까지 낮춰야 하고, 이를 지원하기 위해 메모리 컨트롤러 자체에 새로운 연산/오퍼레이터를 넣는 식의 하드웨어-소프트웨어 협업이 필요하다.
메모리 중심 아키텍처가 열어갈 미래Wong은 “이거 진짜 큰 혁신 기회로 보이네”라고 반응한다. Charles도 “맞다, 이건 하드웨어와 소프트웨어가 같이 설계해야 하는 영역이고, 실제로 논의 중이다”라고 답한다.
(6) 이 솔루션들이 실제 고객/사용자 경험에 주는 그림
Wong이 Meta에 묻는다: “만약 이런 솔루션(HBM 강화, near-memory compute, shared memory)이 실제로 잘 돌아간다면, Meta 고객 경험은 어떻게 달라지나?”
Changkyu (Meta):
새로운 유즈케이스는 이미 보이는 중이다. 긴 context, 에이전트(agentic use), multi-modal 입력(텍스트+이미지+음성 등).
이건 단순 업그레이드가 아니라 workload 성격 자체의 변화다. 이 workload들은 공통적으로 엄청난 메모리 트래픽을 만든다. 그리고 decode 단계가 매우 memory-bound다.
그래서 진짜 승자는 “강력한 compute + HBM 등 고대역폭 메모리 + 첨단 패키징 + 그걸 효율적으로 돌리는 SW”를 모두 통합해서, 단계별(inference prefill vs decode)로 전용 하드웨어 클러스터를 구성(disaggregate)할 수 있는 쪽이 될 거다. 이것이 차세대 효율적인 AI 데이터센터다.
(7) “메모리 중심 컴퓨팅”은 정확히 뭐를 뜻하나?
Wong: “사람마다 메모리 중심 컴퓨팅(memory-centric computing)을 다르게 정의한다. 당신들에겐 뭘 의미하나?”
Changkyu (Meta):
하드웨어 얘기만으로 끝나지 않는다. 소프트웨어/아키텍처 측면에서도 추론(inference)을 한 덩어리로 보지 말고 분해해야 한다.
prefill 단계(프롬프트를 한 번에 처리하는 단계)는 compute-bound라서 병렬 연산이 핵심이고, cost-effective GDDR 기반 GPU 같은 쪽에 어울린다.
decode 단계(토큰을 한 개씩 생성하며 전체 context와 weights를 계속 읽는 단계)는 memory-bound라서 HBM 같은 초고대역폭 메모리 근처에서 돌아야 한다.
즉 “소프트웨어적으로 프리필과 디코드 파이프라인을 분리(disaggregate)하고, 하드웨어를 역할별로 전문화(specialize)하자”라는 게 메모리 중심 아키텍처의 가장 즉각적이고 강력한 변화라고 본다. 이게 차세대 AI 데이터센터 설계 방식이다.
Charles (MemVerge):
우리는 “메모리”를 더 넓게 잡아서, 사실상 메모리와 스토리지를 하나의 연속체로 본다.
컴퓨트는 순간적으로 생겼다가 사라지는 존재(“ephemeral”), 반면 상태(state)와 기억(memory)는 남는다.
그래서 앞으로 AI에서 진짜 중심은 compute가 아니라 state다. 즉 메모리가 곧 플랫폼이다. 이건 곧 “메모리와 스토리지의 경계가 사라진다”로 이어진다. HBF(High-Bandwidth Flash) 같은 것은 그 경계가 흐려지는 대표 사례다.
김호식(SK hynix):
업계는 prefill 전용, decode 전용 등으로 분해된(disaggregated) 시스템으로 갈 거다.
결국 메모리 중심 컴퓨팅은 “메모리와 컴퓨트를 촘촘하게 붙이고, 이질적인(heterogeneous) 도메인 특화 아키텍처(Domain Specific Architecture)로 나뉜 시스템”을 의미하게 될 것이다.
near memory processing은 이미 손에 잡히는 범주에 와 있다. processing in memory(메모리 내부 연산)까지도 향후 나올 수 있고, 곧 ‘near memory computing’ 제품은 실제 시장에 등장할 거라고 본다.
(8) 5년 뒤 어떤 변화가 가장 클까?
질문: “5년 뒤 다시 모이면, 어디가 제일 크게 변해 있을까? 디바이스 기술? 모델 구조? 애플리케이션?”
김호식(SK hynix):
우리는 AI 시대의 정말 초입에 있다. LLM은 첫 챕터일 뿐, 이 다음은 world model(물리 세계를 이해하고 시뮬레이션하는 모델) 같은 형태로 간다. Meta의 Yann LeCun도 world model을 강조한다.
world model은 온 세상을 이해하려 하므로, 더 방대한 메모리/대역폭이 필요하고, 역시 메모리 바운드일 거다.
그 요구를 만족시키려면 “더 높은 대역폭, 더 큰 용량, 더 좋은 효율”의 차세대 메모리/스토리지 융합형 솔루션(HBF 등)이 필요하다. 결국 메모리와 스토리지는 합쳐질 것이며, 그건 새로운 제품 카테고리를 낳는다.
Charles (MemVerge):
향후 3~5년에서 진짜 변혁은 “어떤 사람이 AI를 어떻게 쓰냐(유즈케이스)” 쪽에서 온다.
소비자: 개인화된 AI 동반자(companion), 튜터, 케어 에이전트 등.
엔터프라이즈: Agentic AI 기반 디지털 동료(digital co-worker), 자동화. 이미 기업 고객들은 “AI는 그냥 시범운영”에서 “AI는 회사의 핵심 과제”로 톤이 바뀌었다.
이건 결국 개인별/조직별 맥락(context)을 장기적으로 기억하고 유지해야 하기 때문에, 메모리/스토리지 인프라 수요를 폭증시킨다. AI가 만들어내는 데이터 자체(회화형, 장황한 대화 로그 등)는 앞으로 10년간 전 세계 데이터의 핵심 소스가 될 거라고 본다. 그 데이터는 ‘기억’의 형태라서, 결국 메모리 중심 플랫폼이 핵심이 된다.
Changkyu (Meta):
“승자”는 compute, HBM, 패키징, 소프트웨어까지 전부 붙인 end-to-end co-design 역량을 가진 팀이 될 거다.
새로운 유즈케이스(긴 컨텍스트, 멀티모달, 에이전트)는 공통적으로 메모리 트래픽 폭증과 memory-bound decode를 만든다.
따라서 효율 좋은 메모리 중심 아키텍처를 설계·운영할 수 있는 쪽이 결국 시장을 잡는다.
(9) 마무리 메시지 (Takeaways)
패널 마지막 한 줄씩:
(SK hynix) AI는 이제 완전히 메모리 중심이다. HBM, DRAM만으로는 부족하고, 더 많은 혁신이 필요하다. 이 혁신을 하려면 메모리 업체를 단순 납품업체가 아니라 “공동 설계 파트너”로 대우해야 한다. 기존의 단순 바이어-서플라이어 관계로는 한계가 있다. 에코시스템 전체 협력이 필요하다.
(MemVerge) 모델이 곧 새로운 컴퓨터다. 그리고 이 컴퓨터가 만들어내는 상태(state) / 맥락(context) / 기억(memory)이 앞으로의 데이터 세계의 중심이 된다. 메모리는 이 상태를 붙잡아두는 플랫폼이기 때문에 AI의 중심축이 된다. 메모리와 스토리지의 경계는 흐려질 것이다.
(Meta) AI의 KPI는 이제 FLOPs/s만이 아니다. “token당 비용”, “bandwidth per watt”, “capacity per watt”, “data movement 최소화” 같은 메모리 지표가 일급 KPI가 된다. 그리고 진짜 승부는 하드웨어-소프트웨어-수치표현-모델 전체를 end-to-end로 Co-design해서 데이터 이동을 최소화하는 팀이 가져간다.
Wong(좌장)도 정리한다:
오늘 계속 반복된 메시지는 “AI의 미래는 Compute만이 아니라 Memory에도 막혀 있다”는 것.
메모리 vs 스토리지의 경계가 사라질 것이다.
전체 스택(모델~소프트웨어~하드웨어)을 가로지르는 공통 모델링/최적화가 필요하고, 새로운 유즈케이스가 실제로 그 변화를 강하게 밀어붙일 것이다.
주제: 차세대 반도체 설계 및 제조를 위한 AI 슈퍼컴퓨팅
발표자: Tim Costa (NVIDIA 반도체 엔지니어링 총괄)
주제별 핵심 정리
A. 큰 그림: AI ↔ Semiconductor의 선순환(“AI Supercomputing for Next-gen Semi Design & Mfg.”)
두 개의 트릴리언 달러급 기회: AI Factories(에너지를 지능으로 바꾸는 공장)와 Physical AI(반도체·중장비·자동차·항공 등 실제 제조 변혁). 이 기회를 잡으려면 칩 설계→시스템 통합→공정·툴링 전 흐름에서 혁신이 필요하며, 핵심 도구가 AI supercomputer(가속 컴퓨팅 + AI).
B. NVIDIA의 역할 확장
칩 회사 → 데이터센터 시스템 → AI 인프라 회사로 진화. AI 인프라는 land·power·shell + CPU/GPU/메모리/네트워킹을 포괄하며, 반도체 생태계와의 깊은 협업으로 구축.
C. Blackwell 제조·조립·랙스케일 통합(영상 요점)
EUV 기반 200B 트랜지스터, HBM(12 stack, 1024 IO), TSV, chip-on-chip-on-wafer, wafer-on-substrate, NVLink/NVLink Switch(144 TB/s all-to-all), GB200 트레이, 2톤/130T 트랜지스터/1.2M 부품 등 초대형 패키징·통합 파이프라인을 보여줌.
D. 소프트웨어 스택: CUDA-X 라이브러리와 도메인 가속
CUDA-X = 가속 컴퓨팅의 시작점. 5G/6G(Aerial/Sionna), 기후(Earth-2), 양자(cuQuantum/CUDA-Q) 등과 더불어 반도체 워크로드용 Warp, cuOpt, cuDSS, cuLitho 제공.
파트너 협업 성과(대략적 배수): FEM, 컴퓨테이셔널 리소그래피(최대 20~70X 커널 성능), SPICE/Circuit(최대 30X), Inspection(40X), CFD(~80X, 최신 Cadence 협업), TCAD(최대 100X).
E. 핵심 라이브러리 포인트
cuDSS(Direct Sparse Solver): EA 단계지만 Applied, Cadence, Synopsys, TSMC 채택. reordering ~11X, factorization ~80X 등 대규모 희소계 연산 가속.
cuLitho(Computational Lithography): Synopsys, TSMC 채택. Curvilinear OPC ~58X, Manhattan OPC ~70X(커널 기준). 실제 워크로드는 더 복합적이나 핵심 커널 대폭 가속.
F. TCAD와 AI Physics(PhysicsNeMo)
TCAD는 유체/열/응력/전자기/전기 등 다물리 복합 워크로드; AmgX, FVDB, cuRAND, cuFFT, cuSOLVER, Warp, PhysicsNeMo 등 광범위 CUDA-X를 결합해 가속.
PhysicsNeMo: GPU 최적화된 PyTorch 기반으로 물리 제약을 내재화한 AI 물리 모델 프레임워크. SK hynix 사례: TCAD에 AI Physics 적용해 ~360X 속도 향상 → 가상 설계·재료/공정 탐색을 현실화.
G. Agentic AI로 “엔지니어” 자체를 가속
Cadence(JedAI), Synopsys, Siemens에 NVIDIA의 agentic AI 기술 통합. SK hynix도 NeMo reasoning 등 채택해 반도체 엔지니어 업무 가속.
H. Physical AI와 Digital Twin(제조/데이터센터/로보틱스)
세 가지 컴퓨터: (1) 학습용(모델 트레이닝) (2) 디바이스 탑재용(온디바이스) (3) Digital Twin(정확한 세계 모델·테스트·피드백 루프).
TSMC/MedAI: 2D CAD → 3D FAB 레이아웃, cuOpt로 멀티층 배관 최적화(수개월 단축). Quanta/Wistron/Pegatron: 가상 생산라인 계획(다운타임/비용 절감), 솔더 페이스트 시뮬로 불량 저감, Teamcenter X + Omniverse로 공정 계획. 데이터센터 전력/냉각 DT(Cadence Reality), 로봇 Gym으로 AMR/휴머노이드/비전 에이전트 훈련.
I. NVIDIA×SK 대규모 AI Factory
SK와 5만장+ GPU 규모의 공동 AI Factory: 칩 설계, Sovereign AI, Digital Twin, 로보틱스, Agentic AI 등 광범위 워크로드 지원.
댓글 0
첫번째 댓글을 남겨주세요